 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAND: Data-Efficient and Self-Aware Precondition Induction for Interactive Task Learning
Paper and Code
Sep 11, 2024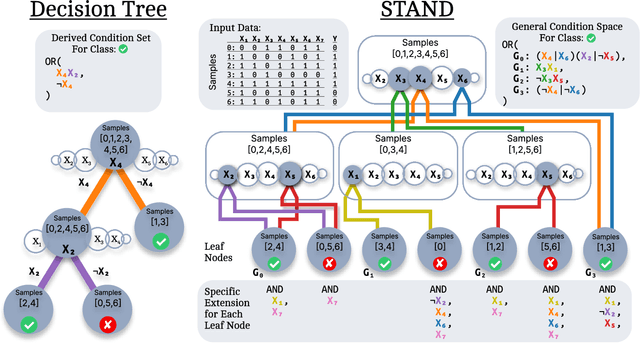

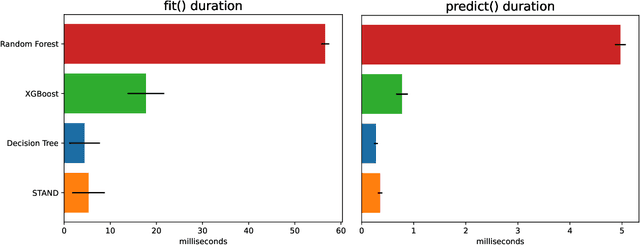
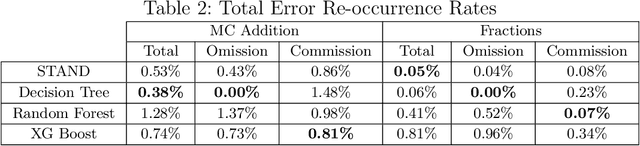
STAND is a data-efficient and computationally efficient machine learning approach that produces better classification accuracy than popular approaches like XGBoost on small-data tabular classification problems like learning rule preconditions from interactive training. STAND accounts for a complete set of good candidate generalizations instead of selecting a single generalization by breaking ties randomly. STAND can use any greedy concept construction strategy, like decision tree learning or sequential covering, and build a structure that approximates a version space over disjunctive normal logical statements. Unlike candidate elimination approaches to version-space learning, STAND does not suffer from issues of version-space collapse from noisy data nor is it restricted to learning strictly conjunctive concepts. More importantly, STAND can produce a measure called instance certainty that can predict increases in holdout set performance and has high utility as an active-learning heuristic. Instance certainty enables STAND to be self-aware of its own learning: it knows when it learns and what example will help it learn the most. We illustrate that instance certainty has desirable properties that can help users select next training problems, and estimate when training is complete in applications where users interactively teach an AI a complex program.