 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSandpiper: Orchestrated AI-Annotation for Educational Discourse at Scale
Mar 09, 2026Digital educational environments are expanding toward complex AI and human discourse, providing researchers with an abundance of data that offers deep insights into learning and instructional processes. However, traditional qualitative analysis remains a labor-intensive bottleneck, severely limiting the scale at which this research can be conducted. We present Sandpiper, a mixed-initiative system designed to serve as a bridge between high-volume conversational data and human qualitative expertise. By tightly coupling interactive researcher dashboards with agentic Large Language Model (LLM) engines, the platform enables scalable analysis without sacrificing methodological rigor. Sandpiper addresses critical barriers to AI adoption in education by implementing context-aware, automated de-identification workflows supported by secure, university-housed infrastructure to ensure data privacy. Furthermore, the system employs schema-constrained orchestration to eliminate LLM hallucinations and enforces strict adherence to qualitative codebooks. An integrated evaluations engine allows for the continuous benchmarking of AI performance against human labels, fostering an iterative approach to model refinement and validation. We propose a user study to evaluate the system's efficacy in improving research efficiency, inter-rater reliability, and researcher trust in AI-assisted qualitative workflows.
AI2T: Building Trustable AI Tutors by Interactively Teaching a Self-Aware Learning Agent
Nov 26, 2024AI2T is an interactively teachable AI for authoring intelligent tutoring systems (ITSs). Authors tutor AI2T by providing a few step-by-step solutions and then grading AI2T's own problem-solving attempts. From just 20-30 minutes of interactive training, AI2T can induce robust rules for step-by-step solution tracking (i.e., model-tracing). As AI2T learns it can accurately estimate its certainty of performing correctly on unseen problem steps using STAND: a self-aware precondition learning algorithm that outperforms state-of-the-art methods like XGBoost. Our user study shows that authors can use STAND's certainty heuristic to estimate when AI2T has been trained on enough diverse problems to induce correct and complete model-tracing programs. AI2T-induced programs are more reliable than hallucination-prone LLMs and prior authoring-by-tutoring approaches. With its self-aware induction of hierarchical rules, AI2T offers a path toward trustable data-efficient authoring-by-tutoring for complex ITSs that normally require as many as 200-300 hours of programming per hour of instruction.
What You Say = What You Want? Teaching Humans to Articulate Requirements for LLMs
Sep 13, 2024



Prompting ChatGPT to achieve complex goals (e.g., creating a customer support chatbot) often demands meticulous prompt engineering, including aspects like fluent writing and chain-of-thought techniques. While emerging prompt optimizers can automatically refine many of these aspects, we argue that clearly conveying customized requirements (e.g., how to handle diverse inputs) remains a human-centric challenge. In this work, we introduce Requirement-Oriented Prompt Engineering (ROPE), a paradigm that focuses human attention on generating clear, complete requirements during prompting. We implement ROPE through an assessment and training suite that provides deliberate practice with LLM-generated feedback. In a study with 30 novices, we show that requirement-focused training doubles novices' prompting performance, significantly outperforming conventional prompt engineering training and prompt optimization. We also demonstrate that high-quality LLM outputs are directly tied to the quality of input requirements. Our work paves the way for more effective task delegation in human-LLM collaborative prompting.
STAND: Data-Efficient and Self-Aware Precondition Induction for Interactive Task Learning
Sep 11, 2024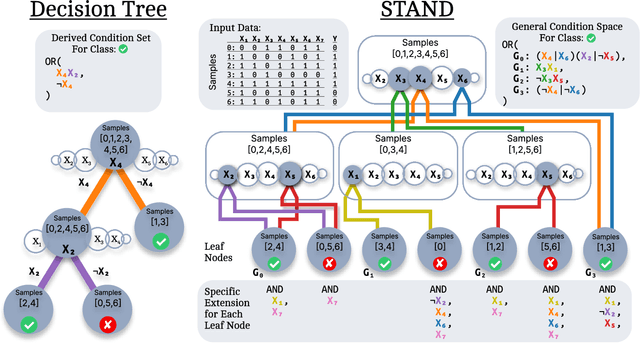

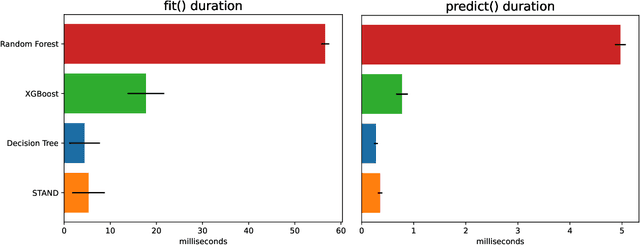
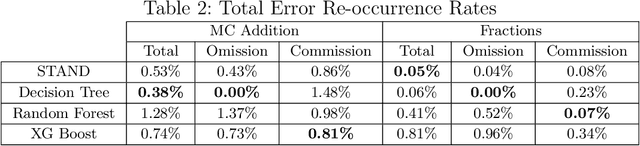
STAND is a data-efficient and computationally efficient machine learning approach that produces better classification accuracy than popular approaches like XGBoost on small-data tabular classification problems like learning rule preconditions from interactive training. STAND accounts for a complete set of good candidate generalizations instead of selecting a single generalization by breaking ties randomly. STAND can use any greedy concept construction strategy, like decision tree learning or sequential covering, and build a structure that approximates a version space over disjunctive normal logical statements. Unlike candidate elimination approaches to version-space learning, STAND does not suffer from issues of version-space collapse from noisy data nor is it restricted to learning strictly conjunctive concepts. More importantly, STAND can produce a measure called instance certainty that can predict increases in holdout set performance and has high utility as an active-learning heuristic. Instance certainty enables STAND to be self-aware of its own learning: it knows when it learns and what example will help it learn the most. We illustrate that instance certainty has desirable properties that can help users select next training problems, and estimate when training is complete in applications where users interactively teach an AI a complex program.
Is AI the better programming partner? Human-Human Pair Programming vs. Human-AI pAIr Programming
Jun 09, 2023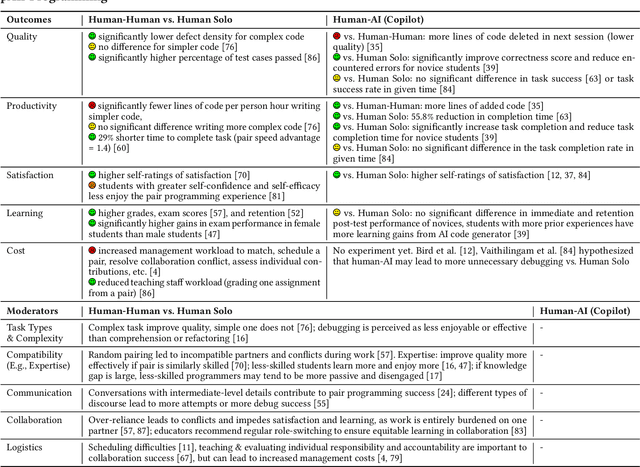
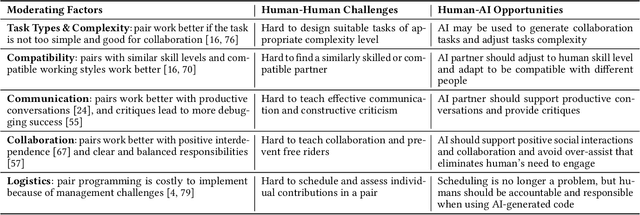
The emergence of large-language models (LLMs) that excel at code generation and commercial products such as GitHub's Copilot has sparked interest in human-AI pair programming (referred to as "pAIr programming") where an AI system collaborates with a human programmer. While traditional pair programming between humans has been extensively studied, it remains uncertain whether its findings can be applied to human-AI pair programming. We compare human-human and human-AI pair programming, exploring their similarities and differences in interaction, measures, benefits, and challenges. We find that the effectiveness of both approaches is mixed in the literature (though the measures used for pAIr programming are not as comprehensive). We summarize moderating factors on the success of human-human pair programming, which provides opportunities for pAIr programming research. For example, mismatched expertise makes pair programming less productive, therefore well-designed AI programming assistants may adapt to differences in expertise levels.
Decomposed Inductive Procedure Learning
Oct 25, 2021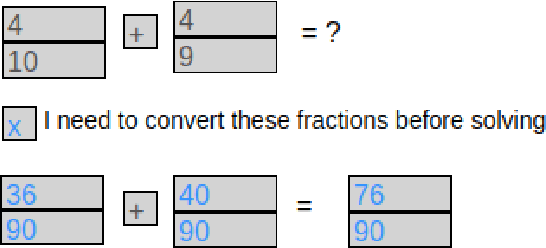
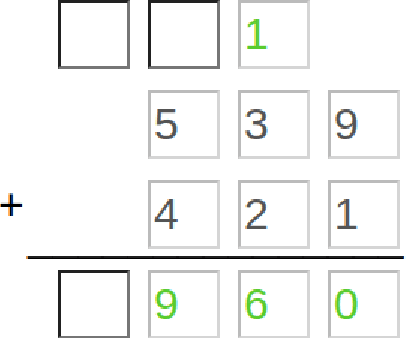
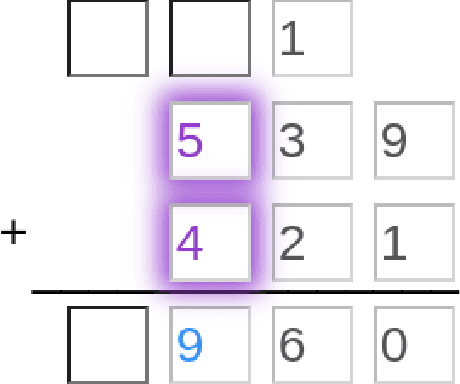
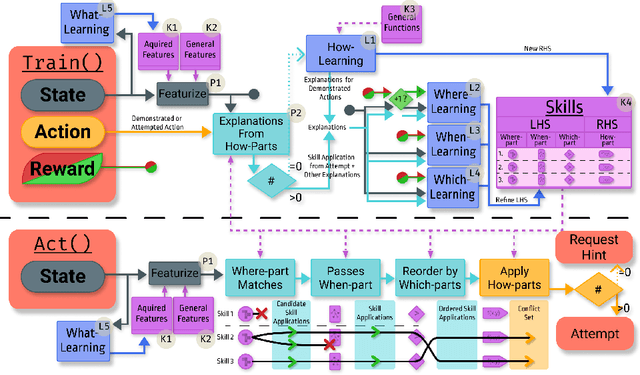
Recent advances in machine learning have made it possible to train artificially intelligent agents that perform with super-human accuracy on a great diversity of complex tasks. However, the process of training these capabilities often necessitates millions of annotated examples -- far more than humans typically need in order to achieve a passing level of mastery on similar tasks. Thus, while contemporary methods in machine learning can produce agents that exhibit super-human performance, their rate of learning per opportunity in many domains is decidedly lower than human-learning. In this work we formalize a theory of Decomposed Inductive Procedure Learning (DIPL) that outlines how different forms of inductive symbolic learning can be used in combination to build agents that learn educationally relevant tasks such as mathematical, and scientific procedures, at a rate similar to human learners. We motivate the construction of this theory along Marr's concepts of the computational, algorithmic, and implementation levels of cognitive modeling, and outline at the computational-level six learning capacities that must be achieved to accurately model human learning. We demonstrate that agents built along the DIPL theory are amenable to satisfying these capacities, and demonstrate, both empirically and theoretically, that DIPL enables the creation of agents that exhibit human-like learning performance.
Learning Cognitive Models using Neural Networks
Jun 21, 2018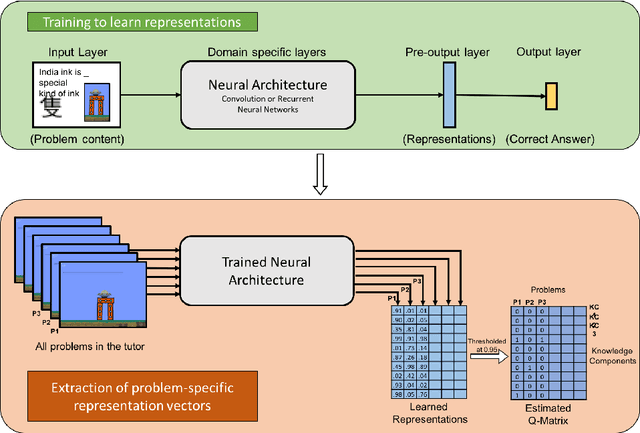

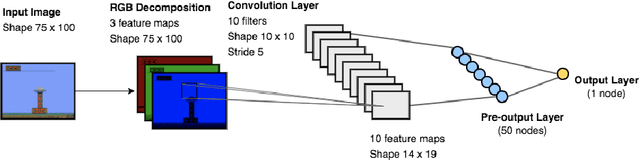
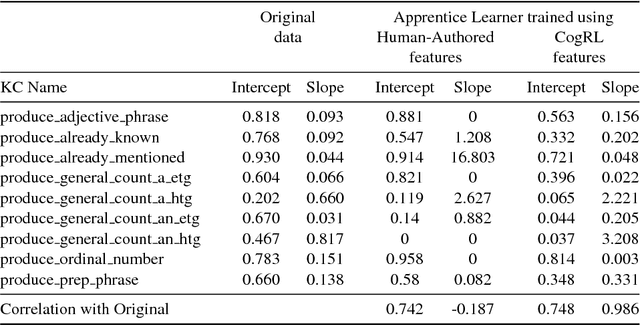
A cognitive model of human learning provides information about skills a learner must acquire to perform accurately in a task domain. Cognitive models of learning are not only of scientific interest, but are also valuable in adaptive online tutoring systems. A more accurate model yields more effective tutoring through better instructional decisions. Prior methods of automated cognitive model discovery have typically focused on well-structured domains, relied on student performance data or involved substantial human knowledge engineering. In this paper, we propose Cognitive Representation Learner (CogRL), a novel framework to learn accurate cognitive models in ill-structured domains with no data and little to no human knowledge engineering. Our contribution is two-fold: firstly, we show that representations learnt using CogRL can be used for accurate automatic cognitive model discovery without using any student performance data in several ill-structured domains: Rumble Blocks, Chinese Character, and Article Selection. This is especially effective and useful in domains where an accurate human-authored cognitive model is unavailable or authoring a cognitive model is difficult. Secondly, for domains where a cognitive model is available, we show that representations learned through CogRL can be used to get accurate estimates of skill difficulty and learning rate parameters without using any student performance data. These estimates are shown to highly correlate with estimates using student performance data on an Article Selection dataset.