 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidelines for Designing AI Technologies to Support Adult Learning
May 06, 2026AI-powered educational technologies have demonstrated measurable benefits for learners, but their design and evaluation have largely centered on K-12 contexts. As a result, many AI-supported learning systems remain poorly aligned with the needs, constraints, and goals of adult learners. To better understand how AI systems function in adult education, this paper examines the deployment of several AI learning technologies developed within a multidisciplinary, national research institute in the United States focused on adult learning and online education. Drawing on longitudinal deployment data, we conducted a reflexive thematic analysis to identify recurring challenges and design considerations across systems. These insights were synthesized into a set of 19 design guidelines intended to inform future AI-supported adult learning technologies. We demonstrate the utility of these guidelines through a heuristic evaluation of the deployed systems. Lastly, we present a guideline exploration tool that aids in the ideation of technologies by connecting the guidelines to stakeholder statements surfaced in the analysis process.
Trust Region Continual Learning as an Implicit Meta-Learner
Feb 02, 2026Continual learning aims to acquire tasks sequentially without catastrophic forgetting, yet standard strategies face a core tradeoff: regularization-based methods (e.g., EWC) can overconstrain updates when task optima are weakly overlapping, while replay-based methods can retain performance but drift due to imperfect replay. We study a hybrid perspective: \emph{trust region continual learning} that combines generative replay with a Fisher-metric trust region constraint. We show that, under local approximations, the resulting update admits a MAML-style interpretation with a single implicit inner step: replay supplies an old-task gradient signal (query-like), while the Fisher-weighted penalty provides an efficient offline curvature shaping (support-like). This yields an emergent meta-learning property in continual learning: the model becomes an initialization that rapidly \emph{re-converges} to prior task optima after each task transition, without explicitly optimizing a bilevel objective. Empirically, on task-incremental diffusion image generation and continual diffusion-policy control, trust region continual learning achieves the best final performance and retention, and consistently recovers early-task performance faster than EWC, replay, and continual meta-learning baselines.
Grounded Concreteness: Human-Like Concreteness Sensitivity in Vision-Language Models
Jan 26, 2026Do vision--language models (VLMs) develop more human-like sensitivity to linguistic concreteness than text-only large language models (LLMs) when both are evaluated with text-only prompts? We study this question with a controlled comparison between matched Llama text backbones and their Llama Vision counterparts across multiple model scales, treating multimodal pretraining as an ablation on perceptual grounding rather than access to images at inference. We measure concreteness effects at three complementary levels: (i) output behavior, by relating question-level concreteness to QA accuracy; (ii) embedding geometry, by testing whether representations organize along a concreteness axis; and (iii) attention dynamics, by quantifying context reliance via attention-entropy measures. In addition, we elicit token-level concreteness ratings from models and evaluate alignment to human norm distributions, testing whether multimodal training yields more human-consistent judgments. Across benchmarks and scales, VLMs show larger gains on more concrete inputs, exhibit clearer concreteness-structured representations, produce ratings that better match human norms, and display systematically different attention patterns consistent with increased grounding.
Taxonomic Networks: A Representation for Neuro-Symbolic Pairing
May 30, 2025We introduce the concept of a \textbf{neuro-symbolic pair} -- neural and symbolic approaches that are linked through a common knowledge representation. Next, we present \textbf{taxonomic networks}, a type of discrimination network in which nodes represent hierarchically organized taxonomic concepts. Using this representation, we construct a novel neuro-symbolic pair and evaluate its performance. We show that our symbolic method learns taxonomic nets more efficiently with less data and compute, while the neural method finds higher-accuracy taxonomic nets when provided with greater resources. As a neuro-symbolic pair, these approaches can be used interchangeably based on situational needs, with seamless translation between them when necessary. This work lays the foundation for future systems that more fundamentally integrate neural and symbolic computation.
* 10 pages, 3 figures, NeuS 2025
TutorGym: A Testbed for Evaluating AI Agents as Tutors and Students
May 02, 2025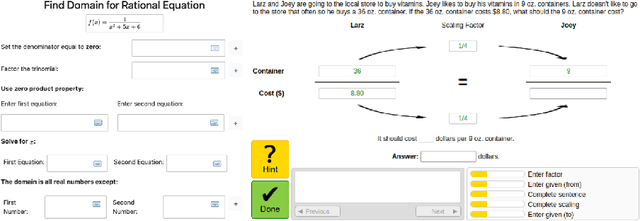
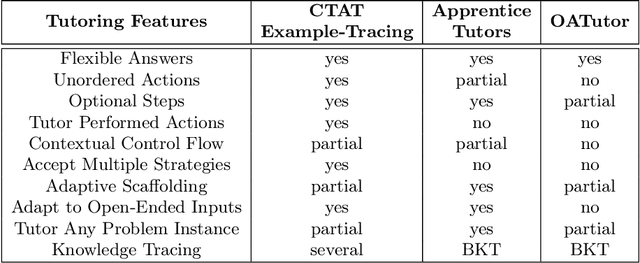
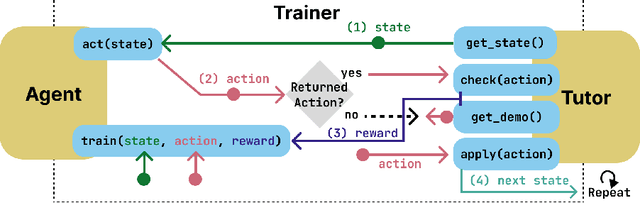
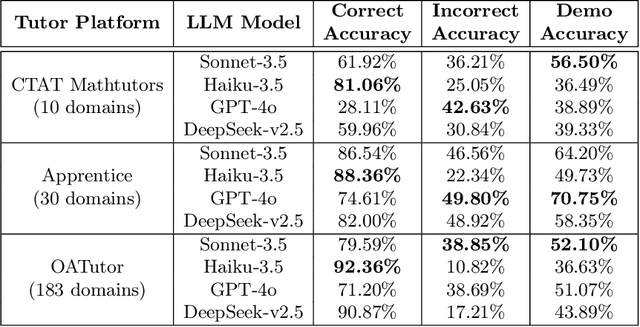
Recent improvements in large language model (LLM) performance on academic benchmarks, such as MATH and GSM8K, have emboldened their use as standalone tutors and as simulations of human learning. However, these new applications require more than evaluations of final solution generation. We introduce TutorGym to evaluate these applications more directly. TutorGym is a standard interface for testing artificial intelligence (AI) agents within existing intelligent tutoring systems (ITS) that have been tested and refined in classroom studies, including Cognitive Tutors (CTAT), Apprentice Tutors, and OATutors. TutorGym is more than a simple problem-solution benchmark, it situates AI agents within the interactive interfaces of existing ITSs. At each step of problem-solving, AI agents are asked what they would do as a tutor or as a learner. As tutors, AI agents are prompted to provide tutoring support -- such as generating examples, hints, and step-level correctness feedback -- which can be evaluated directly against the adaptive step-by-step support provided by existing ITSs. As students, agents directly learn from ITS instruction, and their mistakes and learning trajectories can be compared to student data. TutorGym establishes a common framework for training and evaluating diverse AI agents, including LLMs, computational models of learning, and reinforcement learning agents, within a growing suite of learning environments. Currently, TutorGym includes 223 different tutor domains. In an initial evaluation, we find that current LLMs are poor at tutoring -- none did better than chance at labeling incorrect actions, and next-step actions were correct only ~52-70% of the time -- but they could produce remarkably human-like learning curves when trained as students with in-context learning.
Model Human Learners: Computational Models to Guide Instructional Design
Feb 04, 2025Instructional designers face an overwhelming array of design choices, making it challenging to identify the most effective interventions. To address this issue, I propose the concept of a Model Human Learner, a unified computational model of learning that can aid designers in evaluating candidate interventions. This paper presents the first successful demonstration of this concept, showing that a computational model can accurately predict the outcomes of two human A/B experiments -- one testing a problem sequencing intervention and the other testing an item design intervention. It also demonstrates that such a model can generate learning curves without requiring human data and provide theoretical insights into why an instructional intervention is effective. These findings lay the groundwork for future Model Human Learners that integrate cognitive and learning theories to support instructional design across diverse tasks and interventions.
TRESTLE: A Model of Concept Formation in Structured Domains
Oct 14, 2024
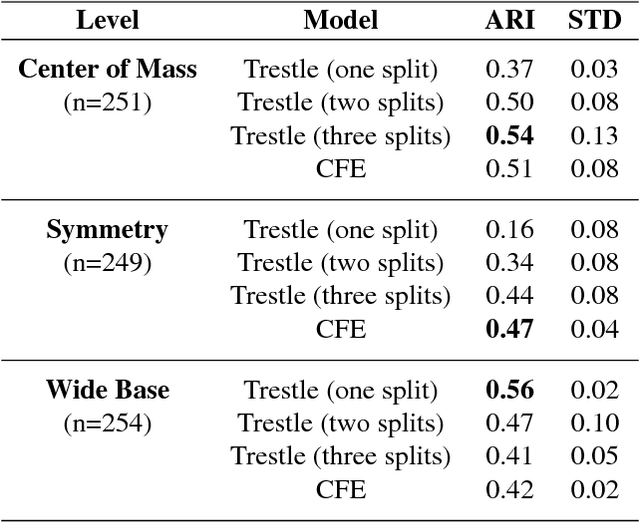


The literature on concept formation has demonstrated that humans are capable of learning concepts incrementally, with a variety of attribute types, and in both supervised and unsupervised settings. Many models of concept formation focus on a subset of these characteristics, but none account for all of them. In this paper, we present TRESTLE, an incremental account of probabilistic concept formation in structured domains that unifies prior concept learning models. TRESTLE works by creating a hierarchical categorization tree that can be used to predict missing attribute values and cluster sets of examples into conceptually meaningful groups. It updates its knowledge by partially matching novel structures and sorting them into its categorization tree. Finally, the system supports mixed-data representations, including nominal, numeric, relational, and component attributes. We evaluate TRESTLE's performance on a supervised learning task and an unsupervised clustering task. For both tasks, we compare it to a nonincremental model and to human participants. We find that this new categorization model is competitive with the nonincremental approach and more closely approximates human behavior on both tasks. These results serve as an initial demonstration of TRESTLE's capabilities and show that, by taking key characteristics of human learning into account, it can better model behavior than approaches that ignore them.
* 20 pages, 6 figures, 1 table
The Impact of an XAI-Augmented Approach on Binary Classification with Scarce Data
Jul 01, 2024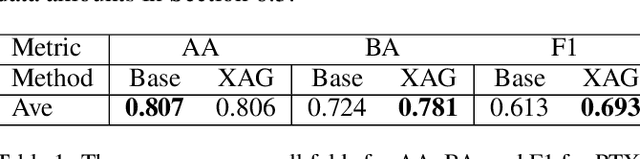
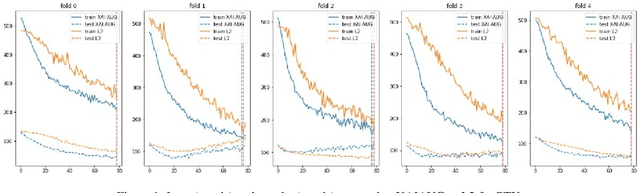

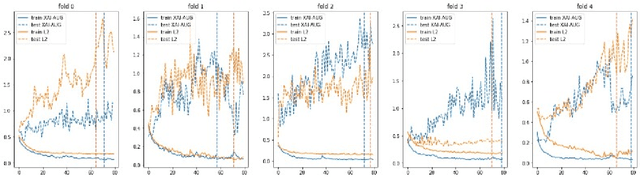
Point-of-Care Ultrasound (POCUS) is the practice of clinicians conducting and interpreting ultrasound scans right at the patient's bedside. However, the expertise needed to interpret these images is considerable and may not always be present in emergency situations. This reality makes algorithms such as machine learning classifiers extremely valuable to augment human decisions. POCUS devices are becoming available at a reasonable cost in the size of a mobile phone. The challenge of turning POCUS devices into life-saving tools is that interpretation of ultrasound images requires specialist training and experience. Unfortunately, the difficulty to obtain positive training images represents an important obstacle to building efficient and accurate classifiers. Hence, the problem we try to investigate is how to explore strategies to increase accuracy of classifiers trained with scarce data. We hypothesize that training with a few data instances may not suffice for classifiers to generalize causing them to overfit. Our approach uses an Explainable AI-Augmented approach to help the algorithm learn more from less and potentially help the classifier better generalize.
Towards Educator-Driven Tutor Authoring: Generative AI Approaches for Creating Intelligent Tutor Interfaces
May 23, 2024Intelligent Tutoring Systems (ITSs) have shown great potential in delivering personalized and adaptive education, but their widespread adoption has been hindered by the need for specialized programming and design skills. Existing approaches overcome the programming limitations with no-code authoring through drag and drop, however they assume that educators possess the necessary skills to design effective and engaging tutor interfaces. To address this assumption we introduce generative AI capabilities to assist educators in creating tutor interfaces that meet their needs while adhering to design principles. Our approach leverages Large Language Models (LLMs) and prompt engineering to generate tutor layout and contents based on high-level requirements provided by educators as inputs. However, to allow them to actively participate in the design process, rather than relying entirely on AI-generated solutions, we allow generation both at the entire interface level and at the individual component level. The former provides educators with a complete interface that can be refined using direct manipulation, while the latter offers the ability to create specific elements to be added to the tutor interface. A small-scale comparison shows the potential of our approach to enhance the efficiency of tutor interface design. Moving forward, we raise critical questions for assisting educators with generative AI capabilities to create personalized, effective, and engaging tutors, ultimately enhancing their adoption.
Cobweb: An Incremental and Hierarchical Model of Human-Like Category Learning
Mar 06, 2024Cobweb, a human like category learning system, differs from other incremental categorization models in constructing hierarchically organized cognitive tree-like structures using the category utility measure. Prior studies have shown that Cobweb can capture psychological effects such as the basic level, typicality, and fan effects. However, a broader evaluation of Cobweb as a model of human categorization remains lacking. The current study addresses this gap. It establishes Cobweb's alignment with classical human category learning effects. It also explores Cobweb's flexibility to exhibit both exemplar and prototype like learning within a single model. These findings set the stage for future research on Cobweb as a comprehensive model of human category learning.