 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Papers Match Code? A Benchmark and Framework for Paper-Code Consistency Detection in Bioinformatics Software
Mar 23, 2026Ensuring consistency between research papers and their corresponding software implementations is fundamental to software reliability and scientific reproducibility. However, this problem remains underexplored, particularly in the domain of bioinformatics, where discrepancies between methodological descriptions in papers and their actual code implementations are prevalent. To address this gap, this paper introduces a new task, namely paper-code consistency detection, and curates a collection of 48 bioinformatics software projects along with their associated publications. We systematically align sentence-level algorithmic descriptions from papers with function-level code snippets. Combined with expert annotations and a hybrid negative sampling strategy, we construct the first benchmark dataset in the bioinformatics domain tailored to this task, termed BioCon. Based on this benchmark, we further propose a cross-modal consistency detection framework designed to model the semantic relationships between natural language descriptions and code implementations. The framework adopts a unified input representation and leverages pre-trained models to capture deep semantic alignment between papers and code. To mitigate the effects of class imbalance and hard samples, we incorporate a weighted focal loss to enhance model robustness. Experimental results demonstrate that our framework effectively identifies consistency between papers and code in bioinformatics, achieving an accuracy of 0.9056 and an F1 score of 0.8011. Overall, this study opens a new research direction for paper-code consistency analysis and lays the foundation for automated reproducibility assessment and cross-modal understanding in scientific software.
Cobweb: An Incremental and Hierarchical Model of Human-Like Category Learning
Mar 06, 2024Cobweb, a human like category learning system, differs from other incremental categorization models in constructing hierarchically organized cognitive tree-like structures using the category utility measure. Prior studies have shown that Cobweb can capture psychological effects such as the basic level, typicality, and fan effects. However, a broader evaluation of Cobweb as a model of human categorization remains lacking. The current study addresses this gap. It establishes Cobweb's alignment with classical human category learning effects. It also explores Cobweb's flexibility to exhibit both exemplar and prototype like learning within a single model. These findings set the stage for future research on Cobweb as a comprehensive model of human category learning.
Avoiding Catastrophic Forgetting in Visual Classification Using Human Concept Formation
Feb 26, 2024Deep neural networks have excelled in machine learning, particularly in vision tasks, however, they often suffer from catastrophic forgetting when learning new tasks sequentially. In this work, we propose Cobweb4V, a novel visual classification approach that builds on Cobweb, a human like learning system that is inspired by the way humans incrementally learn new concepts over time. In this research, we conduct a comprehensive evaluation, showcasing the proficiency of Cobweb4V in learning visual concepts, requiring less data to achieve effective learning outcomes compared to traditional methods, maintaining stable performance over time, and achieving commendable asymptotic behavior, without catastrophic forgetting effects. These characteristics align with learning strategies in human cognition, positioning Cobweb4V as a promising alternative to neural network approaches.
Speech Detection Task Against Asian Hate: BERT the Central, While Data-Centric Studies the Crucial
Jun 05, 2022



With the epidemic continuing, hatred against Asians is intensifying in countries outside Asia, especially among the Chinese. Thus, there is an urgent need to detect and prevent hate speech toward Asians effectively. In this work, we first create COVID-HATE-2022, an annotated dataset that is an extension of the anti-Asian hate speech dataset on Twitter, including 2,035 annotated tweets fetched in early February 2022, which are labeled based on specific criteria, and we present the comprehensive collection of scenarios of hate and non-hate tweets in the dataset. Second, we fine-tune the BERT models based on the relevant datasets, and demonstrate strategies including 1) cleaning the hashtags, usernames being @, URLs, and emojis before the fine-tuning process, and 2) training with the data while validating with the "clean" data (and the opposite) are not effective for improving performance. Third, we investigate the performance of advanced fine-tuning strategies with 1) model-centric approaches, such as discriminative fine-tuning, gradual unfreezing, and warmup steps, and 2) data-centric approaches, which incorporate data trimming and data augmenting, and show that both strategies generally improve the performance, while data-centric ones outperform the others, which demonstrate the feasibility and effectiveness of the data-centric approaches.
Unsupervised Multilingual Alignment using Wasserstein Barycenter
Jan 28, 2020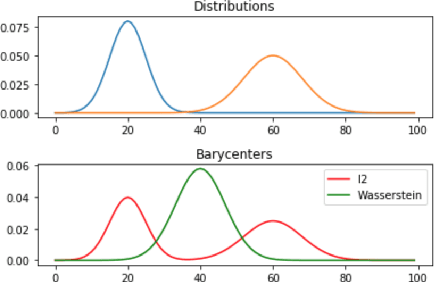

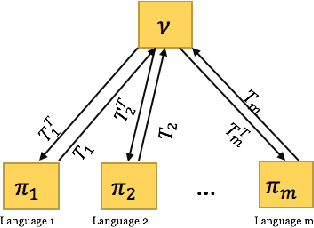
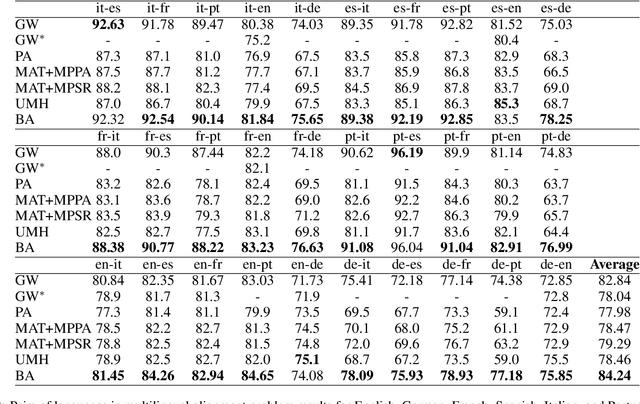
We study unsupervised multilingual alignment, the problem of finding word-to-word translations between multiple languages without using any parallel data. One popular strategy is to reduce multilingual alignment to the much simplified bilingual setting, by picking one of the input languages as the pivot language that we transit through. However, it is well-known that transiting through a poorly chosen pivot language (such as English) may severely degrade the translation quality, since the assumed transitive relations among all pairs of languages may not be enforced in the training process. Instead of going through a rather arbitrarily chosen pivot language, we propose to use the Wasserstein barycenter as a more informative ''mean'' language: it encapsulates information from all languages and minimizes all pairwise transportation costs. We evaluate our method on standard benchmarks and demonstrate state-of-the-art performances.