 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Educational Dialogue Act Classifiers with Low-Resource and Imbalanced Datasets
Paper and Code

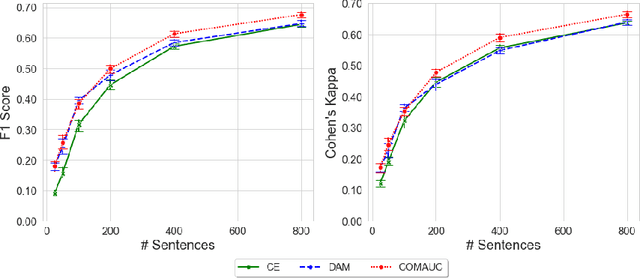
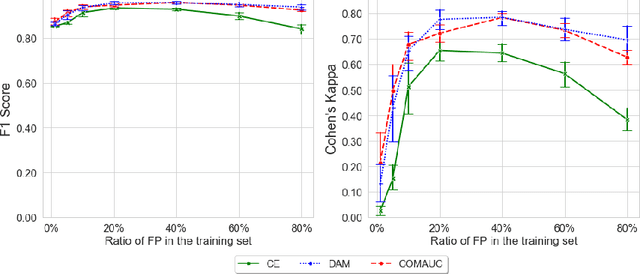

Dialogue acts (DAs) can represent conversational actions of tutors or students that take place during tutoring dialogues. Automating the identification of DAs in tutoring dialogues is significant to the design of dialogue-based intelligent tutoring systems. Many prior studies employ machine learning models to classify DAs in tutoring dialogues and invest much effort to optimize the classification accuracy by using limited amounts of training data (i.e., low-resource data scenario). However, beyond the classification accuracy, the robustness of the classifier is also important, which can reflect the capability of the classifier on learning the patterns from different class distributions. We note that many prior studies on classifying educational DAs employ cross entropy (CE) loss to optimize DA classifiers on low-resource data with imbalanced DA distribution. The DA classifiers in these studies tend to prioritize accuracy on the majority class at the expense of the minority class which might not be robust to the data with imbalanced ratios of different DA classes. To optimize the robustness of classifiers on imbalanced class distributions, we propose to optimize the performance of the DA classifier by maximizing the area under the ROC curve (AUC) score (i.e., AUC maximization). Through extensive experiments, our study provides evidence that (i) by maximizing AUC in the training process, the DA classifier achieves significant performance improvement compared to the CE approach under low-resource data, and (ii) AUC maximization approaches can improve the robustness of the DA classifier under different class imbalance ratios.