 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFMF: World Modeling by Forecasting Vision Foundation Model Features
Dec 12, 2025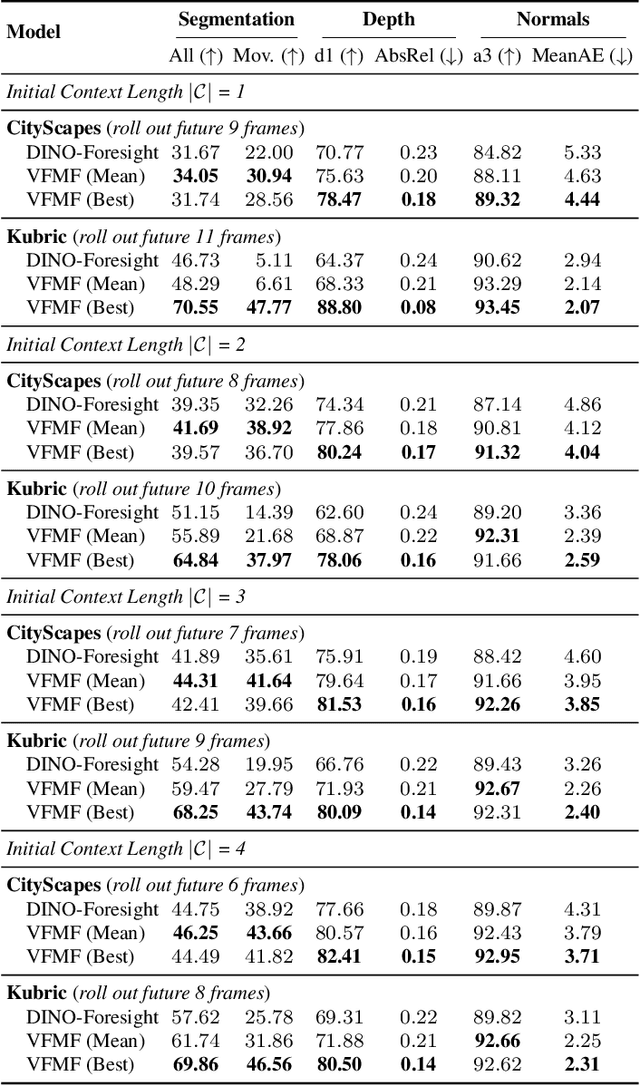

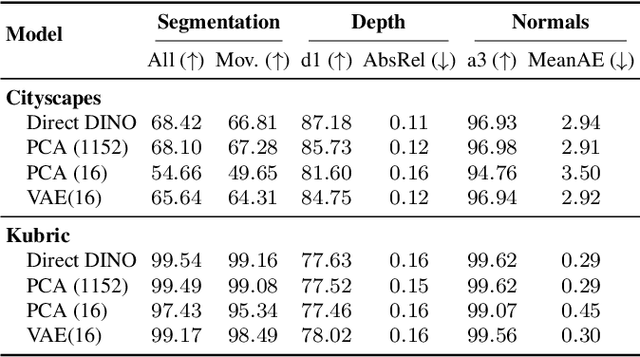
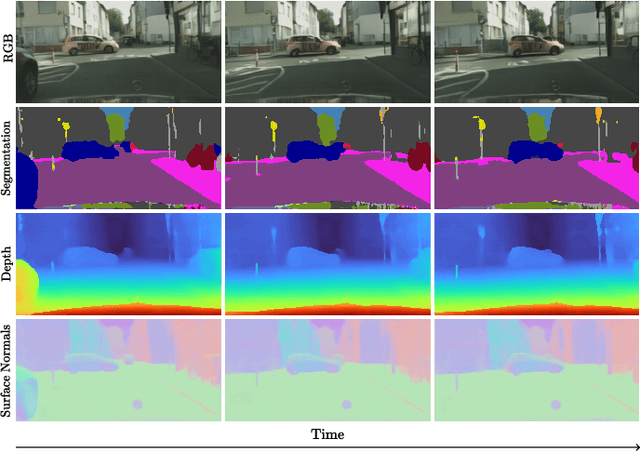
Forecasting from partial observations is central to world modeling. Many recent methods represent the world through images, and reduce forecasting to stochastic video generation. Although such methods excel at realism and visual fidelity, predicting pixels is computationally intensive and not directly useful in many applications, as it requires translating RGB into signals useful for decision making. An alternative approach uses features from vision foundation models (VFMs) as world representations, performing deterministic regression to predict future world states. These features can be directly translated into actionable signals such as semantic segmentation and depth, while remaining computationally efficient. However, deterministic regression averages over multiple plausible futures, undermining forecast accuracy by failing to capture uncertainty. To address this crucial limitation, we introduce a generative forecaster that performs autoregressive flow matching in VFM feature space. Our key insight is that generative modeling in this space requires encoding VFM features into a compact latent space suitable for diffusion. We show that this latent space preserves information more effectively than previously used PCA-based alternatives, both for forecasting and other applications, such as image generation. Our latent predictions can be easily decoded into multiple useful and interpretable output modalities: semantic segmentation, depth, surface normals, and even RGB. With matched architecture and compute, our method produces sharper and more accurate predictions than regression across all modalities. Our results suggest that stochastic conditional generation of VFM features offers a promising and scalable foundation for future world models.
On Vanishing Variance in Transformer Length Generalization
Apr 03, 2025It is a widely known issue that Transformers, when trained on shorter sequences, fail to generalize robustly to longer ones at test time. This raises the question of whether Transformer models are real reasoning engines, despite their impressive abilities in mathematical problem solving and code synthesis. In this paper, we offer a vanishing variance perspective on this issue. To the best of our knowledge, we are the first to demonstrate that even for today's frontier models, a longer sequence length results in a decrease in variance in the output of the multi-head attention modules. On the argmax retrieval and dictionary lookup tasks, our experiments show that applying layer normalization after the attention outputs leads to significantly better length generalization. Our analyses attribute this improvement to a reduction-though not a complete elimination-of the distribution shift caused by vanishing variance.