 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLayR: Scene Layout Generation with Rectified Flow
Paper and Code
Dec 06, 2024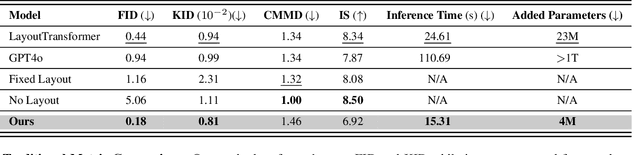
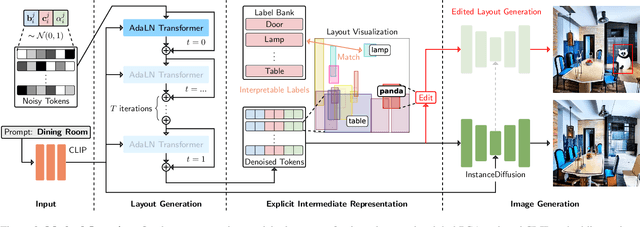
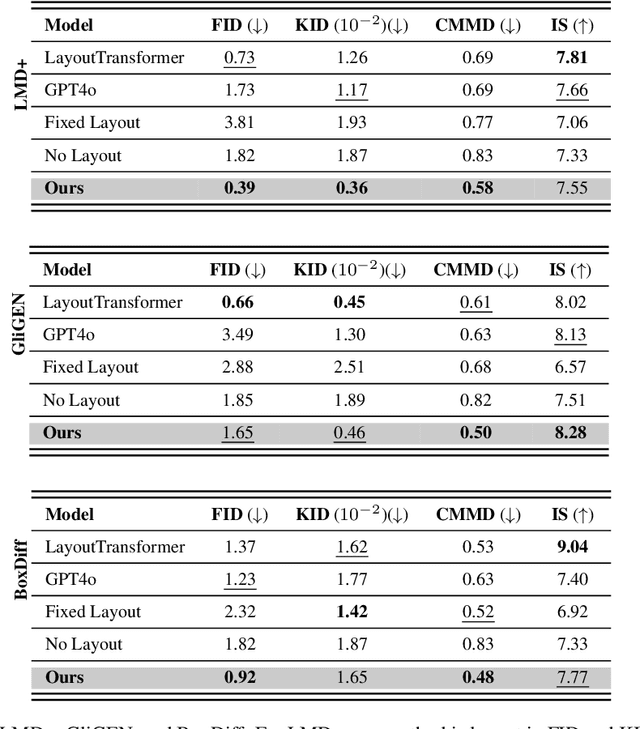
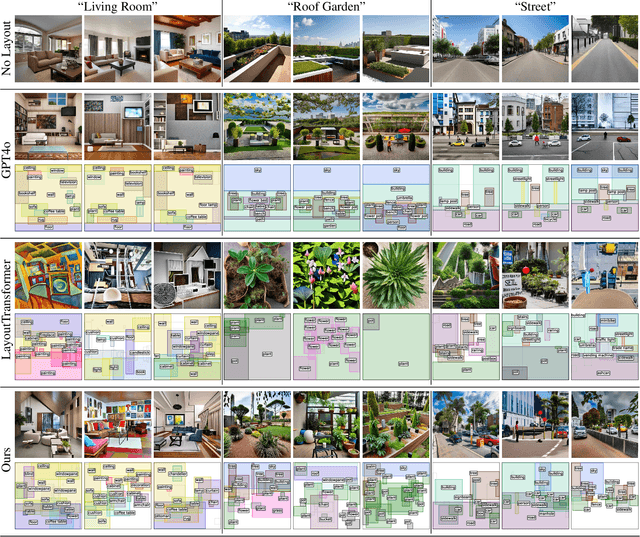
We introduce SLayR, Scene Layout Generation with Rectified flow. State-of-the-art text-to-image models achieve impressive results. However, they generate images end-to-end, exposing no fine-grained control over the process. SLayR presents a novel transformer-based rectified flow model for layout generation over a token space that can be decoded into bounding boxes and corresponding labels, which can then be transformed into images using existing models. We show that established metrics for generated images are inconclusive for evaluating their underlying scene layout, and introduce a new benchmark suite, including a carefully designed repeatable human-evaluation procedure that assesses the plausibility and variety of generated layouts. In contrast to previous works, which perform well in either high variety or plausibility, we show that our approach performs well on both of these axes at the same time. It is also at least 5x times smaller in the number of parameters and 37% faster than the baselines. Our complete text-to-image pipeline demonstrates the added benefits of an interpretable and editable intermediate representation.