 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reinforcement Learning for Unsupervised Controlled Text Generation
Apr 16, 2022
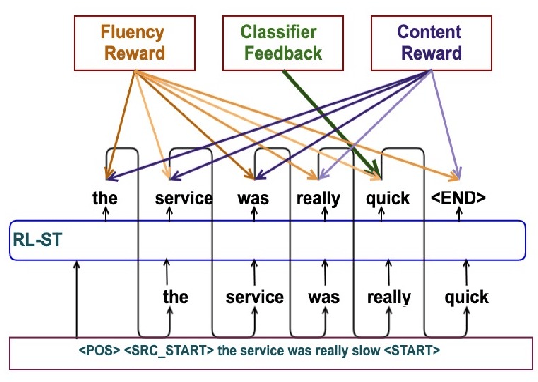
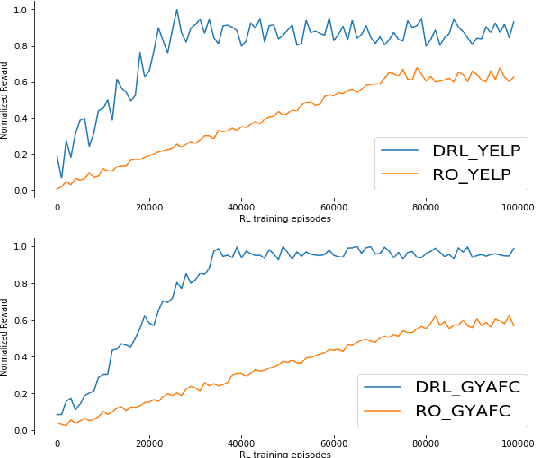

Controlled text generation tasks such as unsupervised text style transfer have increasingly adopted the use of Reinforcement Learning (RL). A major challenge in applying RL to such tasks is the sparse reward, which is available only after the full text is generated. Sparse rewards, combined with a large action space make RL training sample-inefficient and difficult to converge. Recently proposed reward-shaping strategies to address this issue have shown only negligible gains. In contrast, this work proposes a novel approach that provides dense rewards to each generated token. We evaluate our approach by its usage in unsupervised text style transfer. Averaged across datasets, our style transfer system improves upon current state-of-art systems by 21\% on human evaluation and 12\% on automatic evaluation. Upon ablated comparison with the current reward shaping approach (the `roll-out strategy'), using dense rewards improves the overall style transfer quality by 22\% based on human evaluation. Further the RL training is 2.5 times as sample efficient, and 7 times faster.
Transforming Delete, Retrieve, Generate Approach for Controlled Text Style Transfer
Aug 25, 2019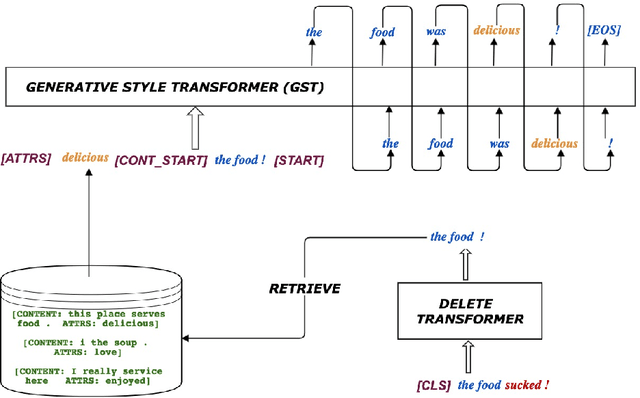
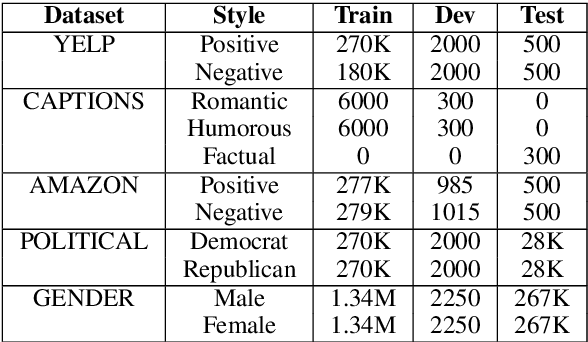

Text style transfer is the task of transferring the style of text having certain stylistic attributes, while preserving non-stylistic or content information. In this work we introduce the Generative Style Transformer (GST) - a new approach to rewriting sentences to a target style in the absence of parallel style corpora. GST leverages the power of both, large unsupervised pre-trained language models as well as the Transformer. GST is a part of a larger `Delete Retrieve Generate' framework, in which we also propose a novel method of deleting style attributes from the source sentence by exploiting the inner workings of the Transformer. Our models outperform state-of-art systems across 5 datasets on sentiment, gender and political slant transfer. We also propose the use of the GLEU metric as an automatic metric of evaluation of style transfer, which we found to compare better with human ratings than the predominantly used BLEU score.
Neural Machine Translation based Word Transduction Mechanisms for Low-Resource Languages
Nov 21, 2018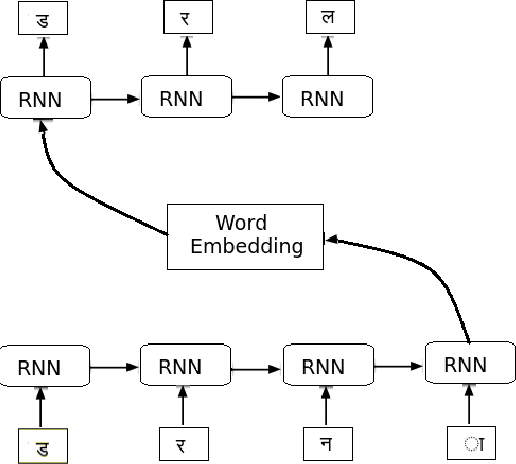


Out-Of-Vocabulary (OOV) words can pose serious challenges for machine translation (MT) tasks, and in particular, for Low-Resource Languages (LRLs). This paper adapts variants of seq2seq models to perform transduction of such words from Hindi to Bhojpuri (an LRL instance), learning from a set of cognate pairs built upon a bilingual dictionary of Hindi-Bhojpuri words. We demonstrate that our models can effectively be used for languages that have a limited amount of parallel corpora, by working at the character-level to grasp phonetic and orthographic similarities across multiple types of word adaptions, whether synchronic or diachronic, loan words or cognates. We provide a comprehensive overview over the training aspects of character-level NMT systems adapted to this task, combined with a detailed analysis of their respective error cases. Using our method, we achieve an improvement by over 6 BLEU on the Hindi-to-Bhojpuri translation task. Further, we show that such transductions generalize well to other languages by applying it successfully to Hindi-Bangla cognate pairs. Our work can be seen as an important step in the process of: (i) resolving the OOV words problem arising in MT tasks, (ii) creating effective parallel corpora for resource-constrained languages, and (iii) leveraging the enhanced semantic knowledge captured by word-level embeddings onto character-level tasks.
Multi Task Deep Morphological Analyzer: Context Aware Joint Morphological Tagging and Lemma Prediction
Nov 21, 2018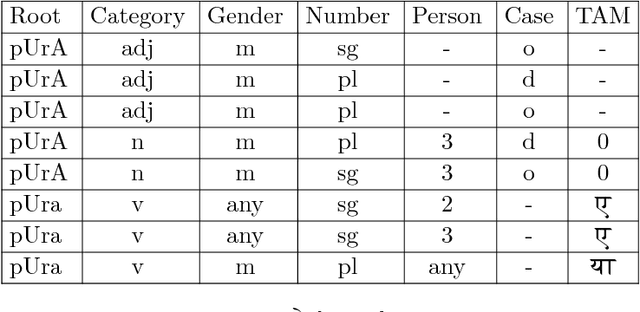
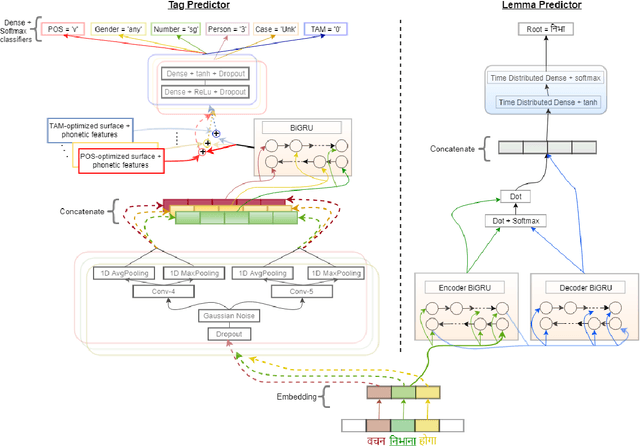
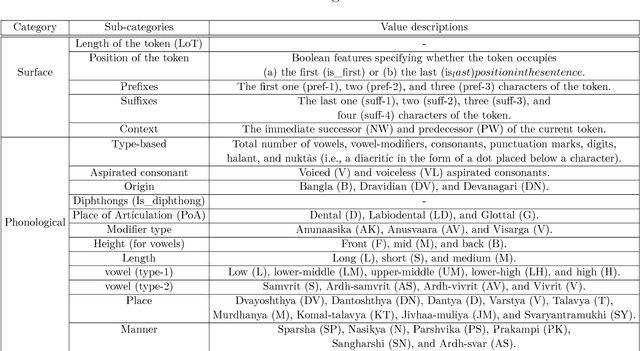
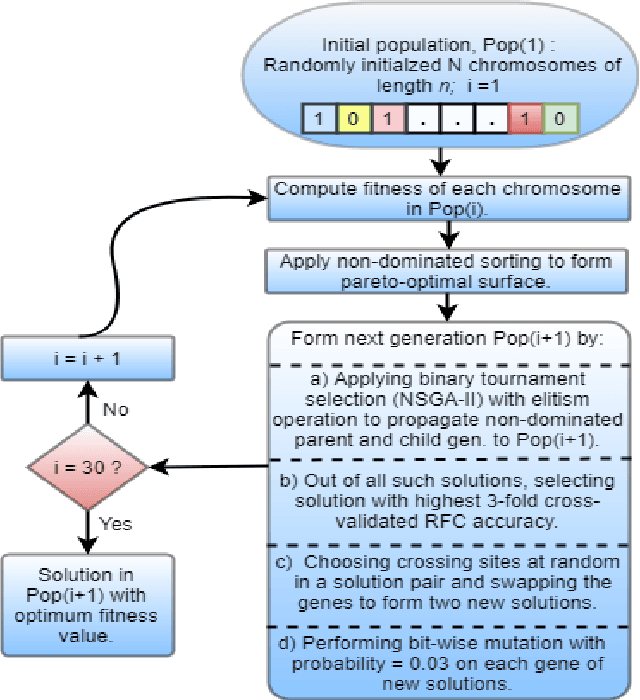
Morphological analysis is an important first step in downstream tasks like machine translation and dependency parsing of morphologically rich languages (MRLs) such as those belonging to Indo-Aryan and Dravidian families. However, the ambiguities introduced by the recombination of morphemes constructing several possible inflections for a word makes the prediction of syntactic traits a notoriously complicated task for MRLs. We propose a character-level neural morphological analyzer, the Multi Task Deep Morphological analyzer (MT-DMA), based on multitask learning of word-level tag markers for Hindi. In order to show the portability of our system to other related languages, we present results on Urdu too. MT-DMA predicts the complete set of morphological tags for words of Indo-Aryan languages: Parts-of-speech (POS), Gender (G), Number (N), Person (P), Case (C), Tense-Aspect-Modality (TAM) marker as well as the Lemma (L) by jointly learning all these in a single end-to-end framework. We show the effectiveness of training of such deep neural networks by the simultaneous optimization of multiple loss functions and sharing of initial parameters for context-aware morphological analysis. Our model outperforms the state-of-art analyzers for Hindi and Urdu. Exploring the use of a set of character-level features in phonological space optimized for each tag through a multi-objective genetic algorithm, coupled with effective training strategies, our model establishes a new state-of-the-art accuracy score upon all seven of the tasks for both the languages. MT-DMA is publicly accessible to be used at http://35.154.251.44/.
Ethical Questions in NLP Research: The -Use of Forensic Linguistics
Dec 20, 2017Ideas from forensic linguistics are now being used frequently in Natural Language Processing (NLP), using machine learning techniques. While the role of forensic linguistics was more benign earlier, it is now being used for purposes which are questionable. Certain methods from forensic linguistics are employed, without considering their scientific limitations and ethical concerns. While we take the specific case of forensic linguistics as an example of such trends in NLP and machine learning, the issue is a larger one and present in many other scientific and data-driven domains. We suggest that such trends indicate that some of the applied sciences are exceeding their legal and scientific briefs. We highlight how carelessly implemented practices are serving to short-circuit the due processes of law as well breach ethical codes.