 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reinforcement Learning for Unsupervised Controlled Text Generation
Paper and Code
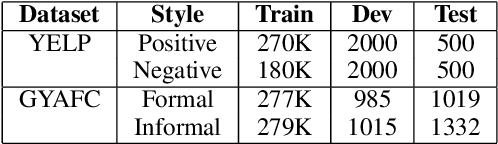
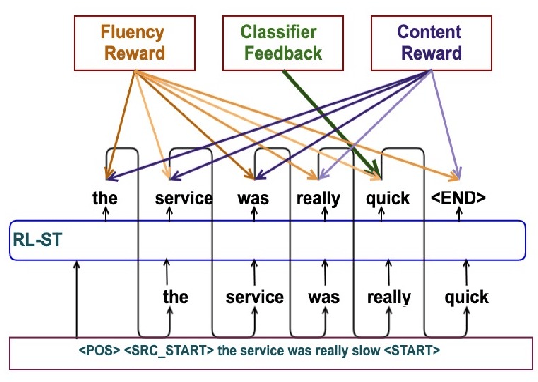
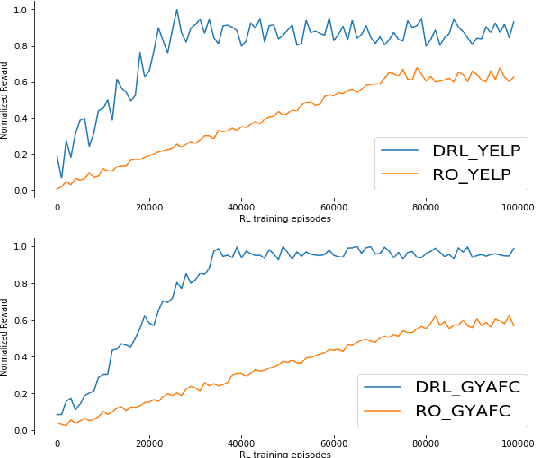

Controlled text generation tasks such as unsupervised text style transfer have increasingly adopted the use of Reinforcement Learning (RL). A major challenge in applying RL to such tasks is the sparse reward, which is available only after the full text is generated. Sparse rewards, combined with a large action space make RL training sample-inefficient and difficult to converge. Recently proposed reward-shaping strategies to address this issue have shown only negligible gains. In contrast, this work proposes a novel approach that provides dense rewards to each generated token. We evaluate our approach by its usage in unsupervised text style transfer. Averaged across datasets, our style transfer system improves upon current state-of-art systems by 21\% on human evaluation and 12\% on automatic evaluation. Upon ablated comparison with the current reward shaping approach (the `roll-out strategy'), using dense rewards improves the overall style transfer quality by 22\% based on human evaluation. Further the RL training is 2.5 times as sample efficient, and 7 times faster.