 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation by Projecting Text into the Same Phonetic-Orthographic Space Using a Common Encoding
May 21, 2023The use of subword embedding has proved to be a major innovation in Neural Machine Translation (NMT). It helps NMT to learn better context vectors for Low Resource Languages (LRLs) so as to predict the target words by better modelling the morphologies of the two languages and also the morphosyntax transfer. Even so, their performance for translation in Indian language to Indian language scenario is still not as good as for resource-rich languages. One reason for this is the relative morphological richness of Indian languages, while another is that most of them fall into the extremely low resource or zero-shot categories. Since most major Indian languages use Indic or Brahmi origin scripts, the text written in them is highly phonetic in nature and phonetically similar in terms of abstract letters and their arrangements. We use these characteristics of Indian languages and their scripts to propose an approach based on common multilingual Latin-based encodings (WX notation) that take advantage of language similarity while addressing the morphological complexity issue in NMT. These multilingual Latin-based encodings in NMT, together with Byte Pair Embedding (BPE) allow us to better exploit their phonetic and orthographic as well as lexical similarities to improve the translation quality by projecting different but similar languages on the same orthographic-phonetic character space. We verify the proposed approach by demonstrating experiments on similar language pairs (Gujarati-Hindi, Marathi-Hindi, Nepali-Hindi, Maithili-Hindi, Punjabi-Hindi, and Urdu-Hindi) under low resource conditions. The proposed approach shows an improvement in a majority of cases, in one case as much as ~10 BLEU points compared to baseline techniques for similar language pairs. We also get up to ~1 BLEU points improvement on distant and zero-shot language pairs.
Exploiting Multilingualism in Low-resource Neural Machine Translation via Adversarial Learning
Mar 31, 2023



Generative Adversarial Networks (GAN) offer a promising approach for Neural Machine Translation (NMT). However, feeding multiple morphologically languages into a single model during training reduces the NMT's performance. In GAN, similar to bilingual models, multilingual NMT only considers one reference translation for each sentence during model training. This single reference translation limits the GAN model from learning sufficient information about the source sentence representation. Thus, in this article, we propose Denoising Adversarial Auto-encoder-based Sentence Interpolation (DAASI) approach to perform sentence interpolation by learning the intermediate latent representation of the source and target sentences of multilingual language pairs. Apart from latent representation, we also use the Wasserstein-GAN approach for the multilingual NMT model by incorporating the model generated sentences of multiple languages for reward computation. This computed reward optimizes the performance of the GAN-based multilingual model in an effective manner. We demonstrate the experiments on low-resource language pairs and find that our approach outperforms the existing state-of-the-art approaches for multilingual NMT with a performance gain of up to 4 BLEU points. Moreover, we use our trained model on zero-shot language pairs under an unsupervised scenario and show the robustness of the proposed approach.
Exploiting Language Relatedness in Machine Translation Through Domain Adaptation Techniques
Mar 03, 2023



One of the significant challenges of Machine Translation (MT) is the scarcity of large amounts of data, mainly parallel sentence aligned corpora. If the evaluation is as rigorous as resource-rich languages, both Neural Machine Translation (NMT) and Statistical Machine Translation (SMT) can produce good results with such large amounts of data. However, it is challenging to improve the quality of MT output for low resource languages, especially in NMT and SMT. In order to tackle the challenges faced by MT, we present a novel approach of using a scaled similarity score of sentences, especially for related languages based on a 5-gram KenLM language model with Kneser-ney smoothing technique for filtering in-domain data from out-of-domain corpora that boost the translation quality of MT. Furthermore, we employ other domain adaptation techniques such as multi-domain, fine-tuning and iterative back-translation approach to compare our novel approach on the Hindi-Nepali language pair for NMT and SMT. Our approach succeeds in increasing ~2 BLEU point on multi-domain approach, ~3 BLEU point on fine-tuning for NMT and ~2 BLEU point on iterative back-translation approach.
BPFISH: Blockchain and Privacy-preserving FL Inspired Smart Healthcare
Jul 27, 2022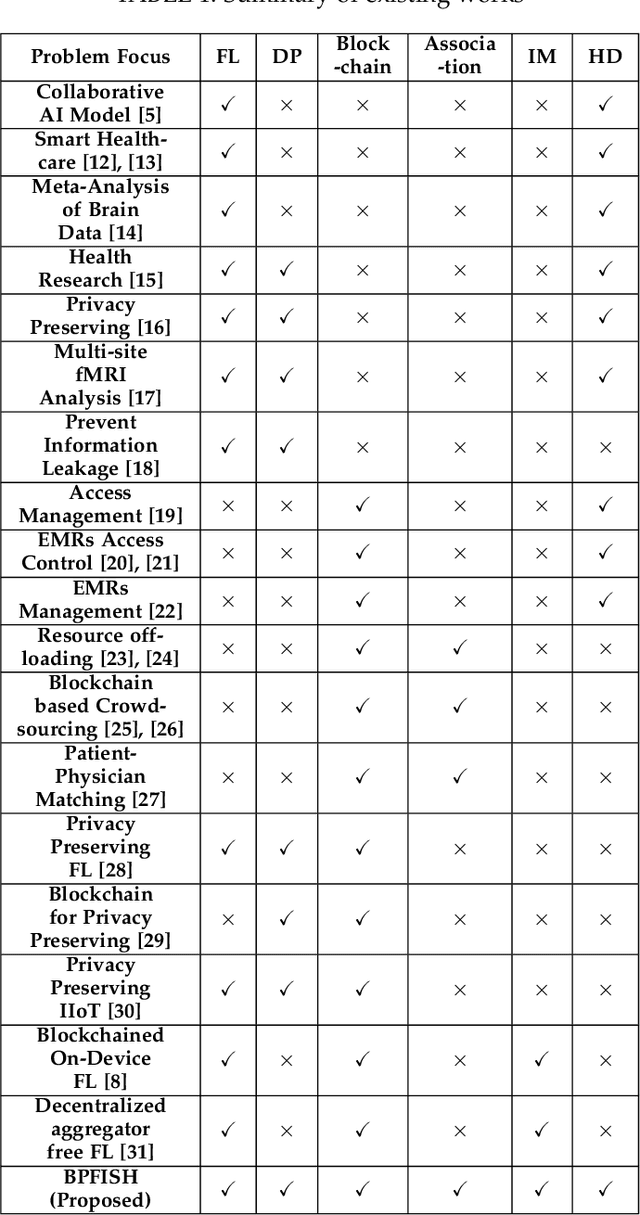
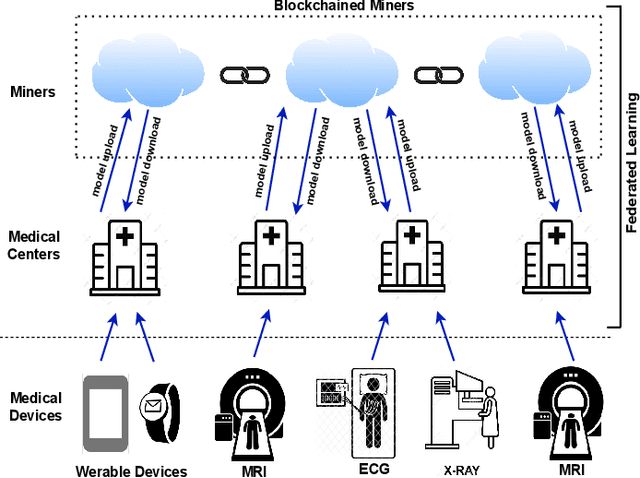

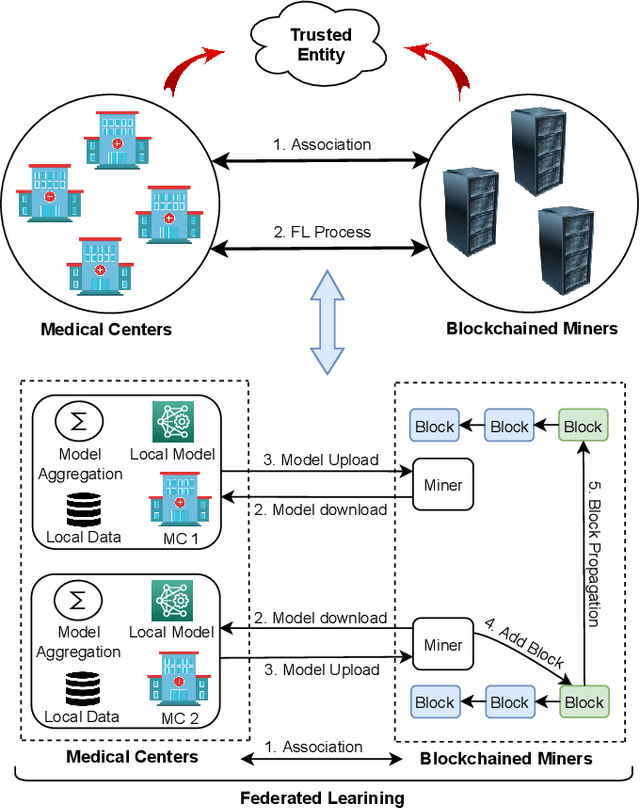
This paper proposes Federated Learning (FL) based smart healthcare system where Medical Centers (MCs) train the local model using the data collected from patients and send the model weights to the miners in a blockchain-based robust framework without sharing raw data, keeping privacy preservation into deliberation. We formulate an optimization problem by maximizing the utility and minimizing the loss function considering energy consumption and FL process delay of MCs for learning effective models on distributed healthcare data underlying a blockchain-based framework. We propose a solution in two stages: first, offer a stable matching-based association algorithm to maximize the utility of both miners and MCs and then solve loss minimization using Stochastic Gradient Descent (SGD) algorithm employing FL under Differential Privacy (DP) and blockchain technology. Moreover, we incorporate blockchain technology to provide tempered resistant and decentralized model weight sharing in the proposed FL-based framework. The effectiveness of the proposed model is shown through simulation on real-world healthcare data comparing other state-of-the-art techniques.
Criticality and Utility-aware Fog Computing System for Remote Health Monitoring
May 24, 2021
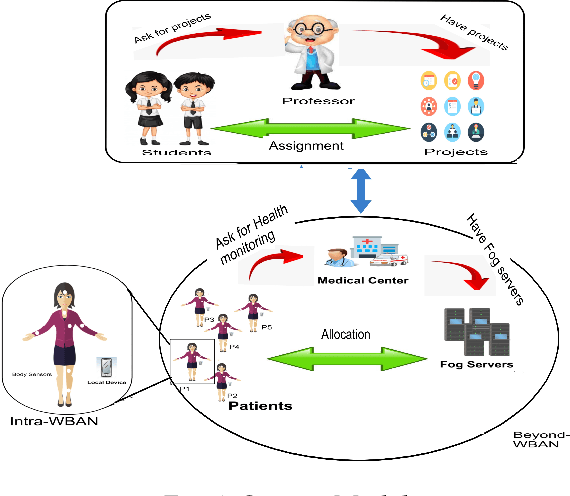

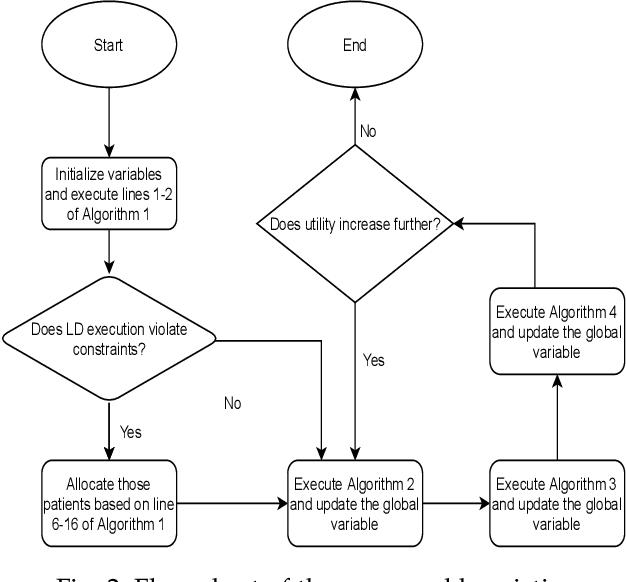
Growing remote health monitoring system allows constant monitoring of the patient's condition and performance of preventive and control check-ups outside medical facilities. However, the real-time smart-healthcare application poses a delay constraint that has to be solved efficiently. Fog computing is emerging as an efficient solution for such real-time applications. Moreover, different medical centers are getting attracted to the growing IoT-based remote healthcare system in order to make a profit by hiring Fog computing resources. However, there is a need for an efficient algorithmic model for allocation of limited fog computing resources in the criticality-aware smart-healthcare system considering the profit of medical centers. Thus, the objective of this work is to maximize the system utility calculated as a linear combination of the profit of the medical center and the loss of patients. To measure profit, we propose a flat-pricing-based model. Further, we propose a swapping-based heuristic to maximize the system utility. The proposed heuristic is tested on various parameters and shown to perform close to the optimal with criticality-awareness in its core. Through extensive simulations, we show that the proposed heuristic achieves an average utility of $96\%$ of the optimal, in polynomial time complexity.