 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Phenotypic Models of Cardiovascular Disease and Obstructive Sleep Apnea Comorbidities: A Longitudinal Wisconsin Sleep Cohort Study
Jun 19, 2024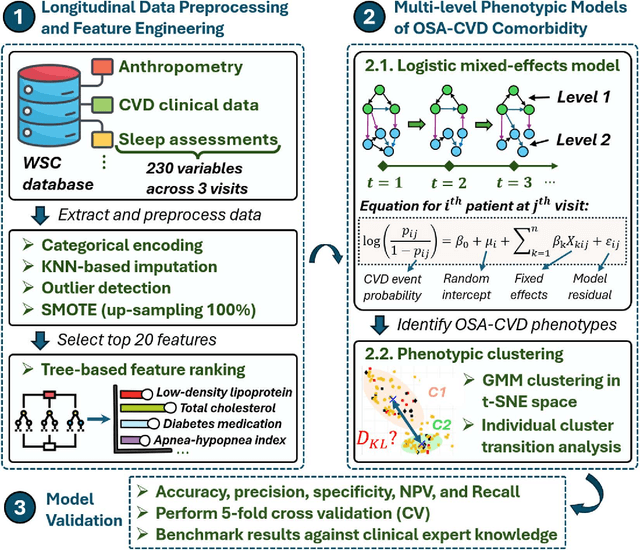
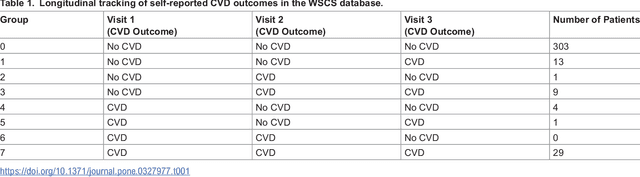
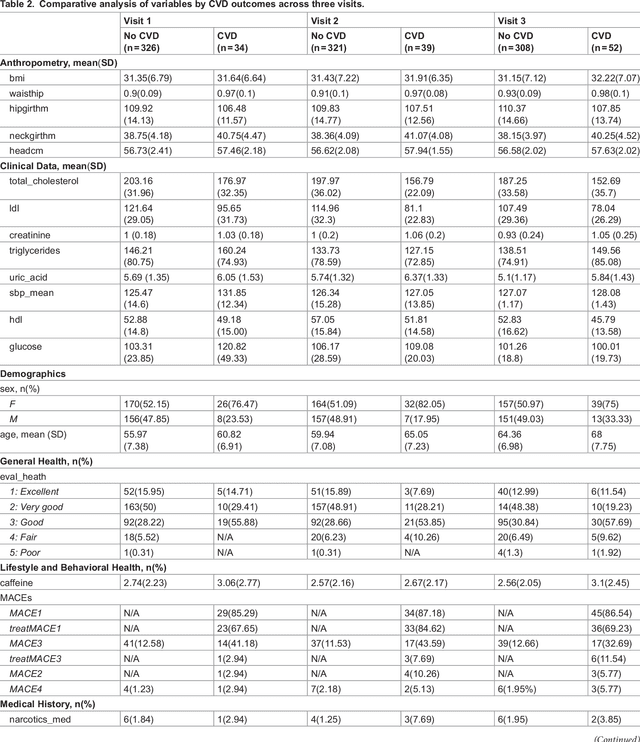
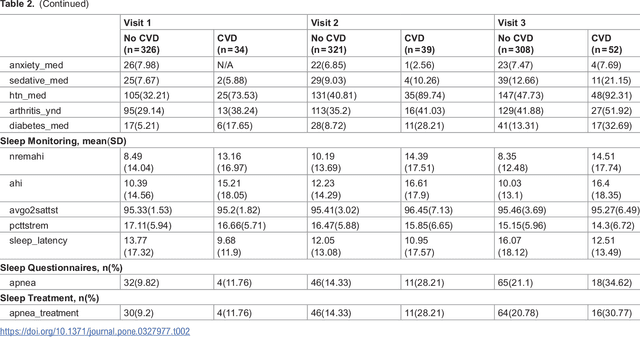
Cardiovascular diseases (CVDs) are notably prevalent among patients with obstructive sleep apnea (OSA), posing unique challenges in predicting CVD progression due to the intricate interactions of comorbidities. Traditional models typically lack the necessary dynamic and longitudinal scope to accurately forecast CVD trajectories in OSA patients. This study introduces a novel multi-level phenotypic model to analyze the progression and interplay of these conditions over time, utilizing data from the Wisconsin Sleep Cohort, which includes 1,123 participants followed for decades. Our methodology comprises three advanced steps: (1) Conducting feature importance analysis through tree-based models to underscore critical predictive variables like total cholesterol, low-density lipoprotein (LDL), and diabetes. (2) Developing a logistic mixed-effects model (LGMM) to track longitudinal transitions and pinpoint significant factors, which displayed a diagnostic accuracy of 0.9556. (3) Implementing t-distributed Stochastic Neighbor Embedding (t-SNE) alongside Gaussian Mixture Models (GMM) to segment patient data into distinct phenotypic clusters that reflect varied risk profiles and disease progression pathways. This phenotypic clustering revealed two main groups, with one showing a markedly increased risk of major adverse cardiovascular events (MACEs), underscored by the significant predictive role of nocturnal hypoxia and sympathetic nervous system activity from sleep data. Analysis of transitions and trajectories with t-SNE and GMM highlighted different progression rates within the cohort, with one cluster progressing more slowly towards severe CVD states than the other. This study offers a comprehensive understanding of the dynamic relationship between CVD and OSA, providing valuable tools for predicting disease onset and tailoring treatment approaches.
An Investigation of Supervised Learning Methods for Authorship Attribution in Short Hinglish Texts using Char & Word N-grams
Dec 26, 2018

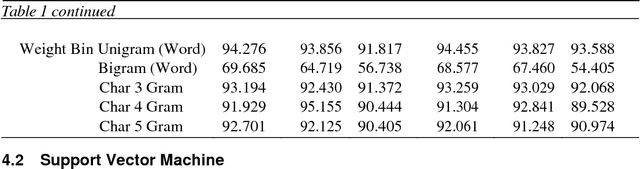

The writing style of a person can be affirmed as a unique identity indicator; the words used, and the structuring of the sentences are clear measures which can identify the author of a specific work. Stylometry and its subset - Authorship Attribution, have a long history beginning from the 19th century, and we can still find their use in modern times. The emergence of the Internet has shifted the application of attribution studies towards non-standard texts that are comparatively shorter to and different from the long texts on which most research has been done. The aim of this paper focuses on the study of short online texts, retrieved from messaging application called WhatsApp and studying the distinctive features of a macaronic language (Hinglish), using supervised learning methods and then comparing the models. Various features such as word n-gram and character n-gram are compared via methods viz., Naive Bayes Classifier, Support Vector Machine, Conditional Tree, and Random Forest, to find the best discriminator for such corpora. Our results showed that SVM attained a test accuracy of up to 95.079% while similarly, Naive Bayes attained an accuracy of up to 94.455% for the dataset. Conditional Tree & Random Forest failed to perform as well as expected. We also found that word unigram and character 3-grams features were more likely to distinguish authors accurately than other features.