 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Supervised Learning Methods for Authorship Attribution in Short Hinglish Texts using Char & Word N-grams
Paper and Code
Dec 26, 2018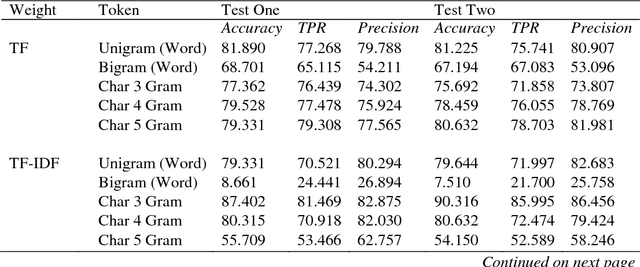

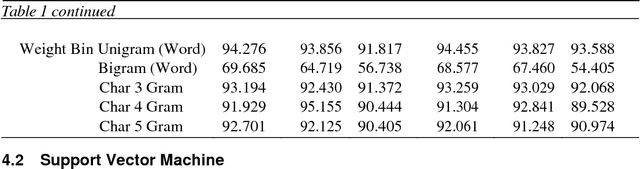

The writing style of a person can be affirmed as a unique identity indicator; the words used, and the structuring of the sentences are clear measures which can identify the author of a specific work. Stylometry and its subset - Authorship Attribution, have a long history beginning from the 19th century, and we can still find their use in modern times. The emergence of the Internet has shifted the application of attribution studies towards non-standard texts that are comparatively shorter to and different from the long texts on which most research has been done. The aim of this paper focuses on the study of short online texts, retrieved from messaging application called WhatsApp and studying the distinctive features of a macaronic language (Hinglish), using supervised learning methods and then comparing the models. Various features such as word n-gram and character n-gram are compared via methods viz., Naive Bayes Classifier, Support Vector Machine, Conditional Tree, and Random Forest, to find the best discriminator for such corpora. Our results showed that SVM attained a test accuracy of up to 95.079% while similarly, Naive Bayes attained an accuracy of up to 94.455% for the dataset. Conditional Tree & Random Forest failed to perform as well as expected. We also found that word unigram and character 3-grams features were more likely to distinguish authors accurately than other features.