 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraRec: Interactive Recommendations Using Multimodal Large Language Models
Feb 26, 2024



Weblogs, comprised of records detailing user activities on any website, offer valuable insights into user preferences, behavior, and interests. Numerous recommendation algorithms, employing strategies such as collaborative filtering, content-based filtering, and hybrid methods, leverage the data mined through these weblogs to provide personalized recommendations to users. Despite the abundance of information available in these weblogs, identifying and extracting pertinent information and key features necessitates extensive engineering endeavors. The intricate nature of the data also poses a challenge for interpretation, especially for non-experts. In this study, we introduce a sophisticated and interactive recommendation framework denoted as InteraRec, which diverges from conventional approaches that exclusively depend on weblogs for recommendation generation. This framework captures high-frequency screenshots of web pages as users navigate through a website. Leveraging state-of-the-art multimodal large language models (MLLMs), it extracts valuable insights into user preferences from these screenshots by generating a user behavioral summary based on predefined keywords. Subsequently, this summary is utilized as input to an LLM-integrated optimization setup to generate tailored recommendations. Through our experiments, we demonstrate the effectiveness of InteraRec in providing users with valuable and personalized offerings.
InteraSSort: Interactive Assortment Planning Using Large Language Models
Nov 20, 2023


Assortment planning, integral to multiple commercial offerings, is a key problem studied in e-commerce and retail settings. Numerous variants of the problem along with their integration into business solutions have been thoroughly investigated in the existing literature. However, the nuanced complexities of in-store planning and a lack of optimization proficiency among store planners with strong domain expertise remain largely overlooked. These challenges frequently necessitate collaborative efforts with multiple stakeholders which often lead to prolonged decision-making processes and significant delays. To mitigate these challenges and capitalize on the advancements of Large Language Models (LLMs), we propose an interactive assortment planning framework, InteraSSort that augments LLMs with optimization tools to assist store planners in making decisions through interactive conversations. Specifically, we develop a solution featuring a user-friendly interface that enables users to express their optimization objectives as input text prompts to InteraSSort and receive tailored optimized solutions as output. Our framework extends beyond basic functionality by enabling the inclusion of additional constraints through interactive conversation, facilitating precise and highly customized decision-making. Extensive experiments demonstrate the effectiveness of our framework and potential extensions to a broad range of operations management challenges.
AI Personification: Estimating the Personality of Language Models
Apr 25, 2022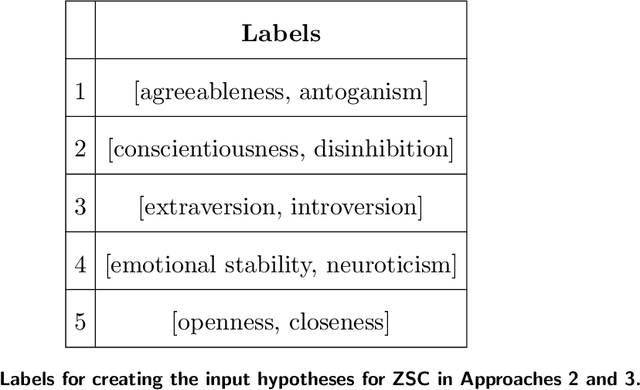
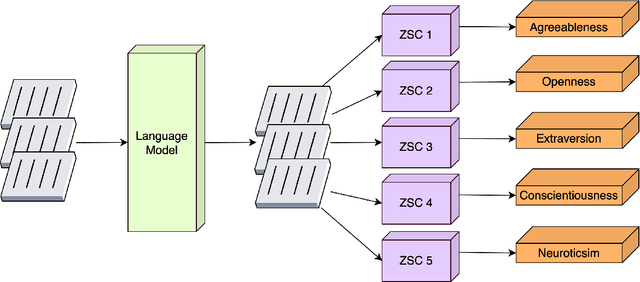
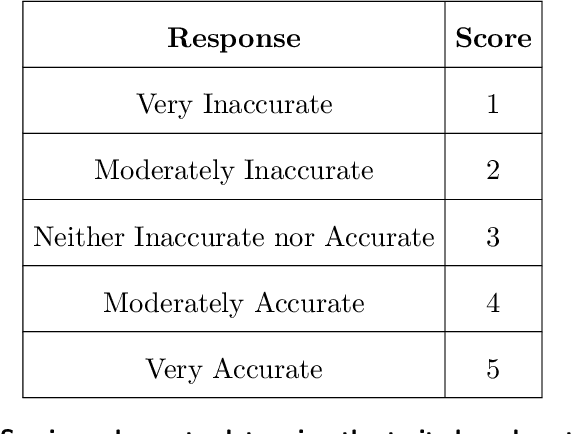
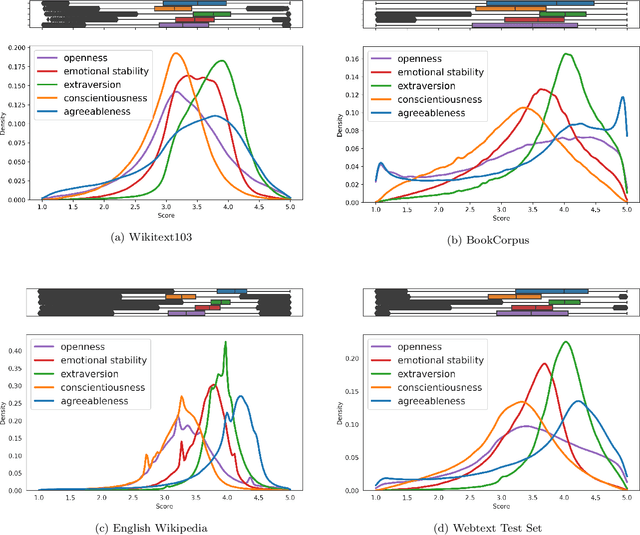
Technology for open-ended language generation, a key application of artificial intelligence, has advanced to a great extent in recent years. Large-scale language models, which are trained on large corpora of text, are being used in a wide range of applications everywhere, from virtual assistants to conversational bots. While these language models output fluent text, existing research shows that these models can and do capture human biases. Many of these biases, especially those that could potentially cause harm, are being well investigated. On the other hand, studies that infer and change personality traits inherited by these models have been scarce or non-existent. In this work, we explore the personality traits of several large-scale language models designed for open-ended text generation and the datasets used for training them. Our work builds on the popular Big Five factors and develops robust methods that quantify the personality traits of these models and their underlying datasets. In particular, we trigger the models with a questionnaire designed for personality assessment and subsequently classify the text responses into quantifiable traits using a Zero-shot classifier. Our classification sheds light on an important anthropomorphic element found in such AI models and can help stakeholders decide how they should be applied and how society could perceive them. We augment our analysis by studying approaches that can alter these personalities.
Choice-Aware User Engagement Modeling andOptimization on Social Media
Apr 01, 2021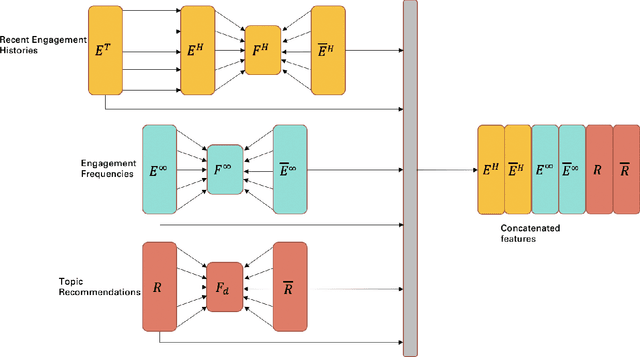
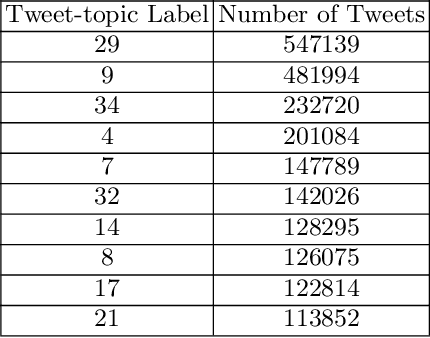

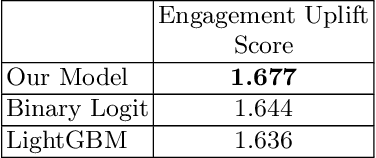
We address the problem of maximizing user engagement with content (in the form of like, reply, retweet, and retweet with comments)on the Twitter platform. We formulate the engagement forecasting task as a multi-label classification problem that captures choice behavior on an unsupervised clustering of tweet-topics. We propose a neural network architecture that incorporates user engagement history and predicts choice conditional on this context. We study the impact of recommend-ing tweets on engagement outcomes by solving an appropriately defined sweet optimization problem based on the proposed model using a large dataset obtained from Twitter.