 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Personification: Estimating the Personality of Language Models
Paper and Code
Apr 25, 2022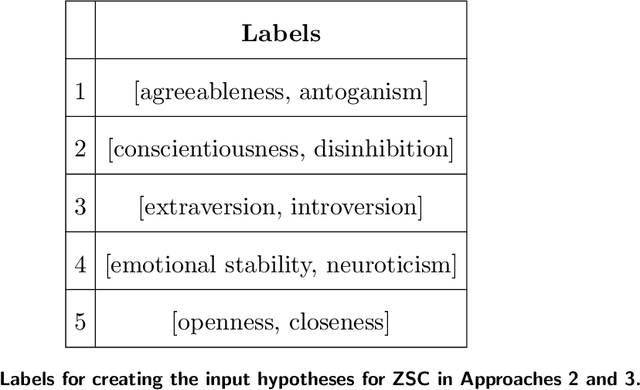
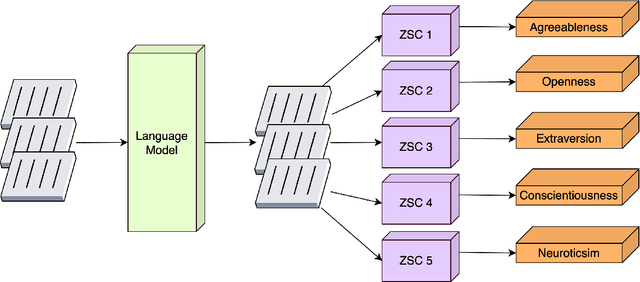
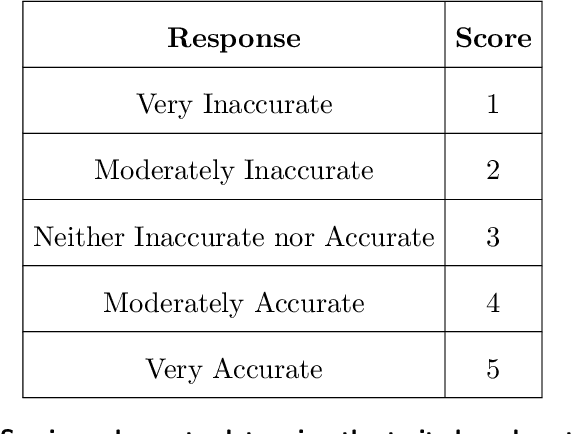
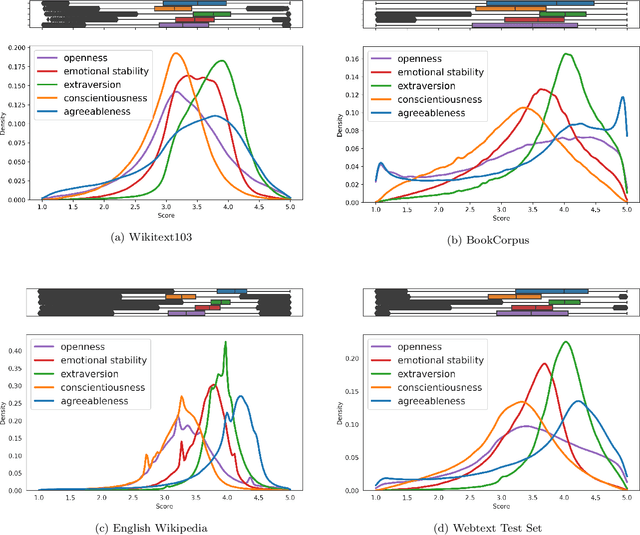
Technology for open-ended language generation, a key application of artificial intelligence, has advanced to a great extent in recent years. Large-scale language models, which are trained on large corpora of text, are being used in a wide range of applications everywhere, from virtual assistants to conversational bots. While these language models output fluent text, existing research shows that these models can and do capture human biases. Many of these biases, especially those that could potentially cause harm, are being well investigated. On the other hand, studies that infer and change personality traits inherited by these models have been scarce or non-existent. In this work, we explore the personality traits of several large-scale language models designed for open-ended text generation and the datasets used for training them. Our work builds on the popular Big Five factors and develops robust methods that quantify the personality traits of these models and their underlying datasets. In particular, we trigger the models with a questionnaire designed for personality assessment and subsequently classify the text responses into quantifiable traits using a Zero-shot classifier. Our classification sheds light on an important anthropomorphic element found in such AI models and can help stakeholders decide how they should be applied and how society could perceive them. We augment our analysis by studying approaches that can alter these personalities.