 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Monocular Localization of Drones by Adapting Domain Maps to Depth Prediction Inaccuracies
Paper and Code
Oct 27, 2022

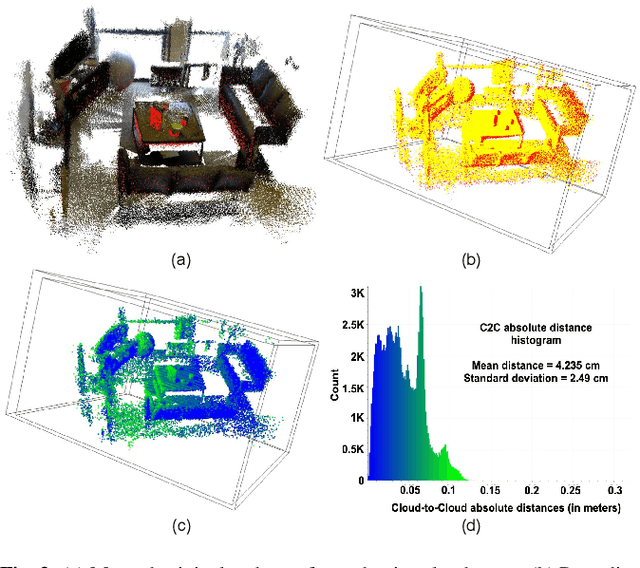
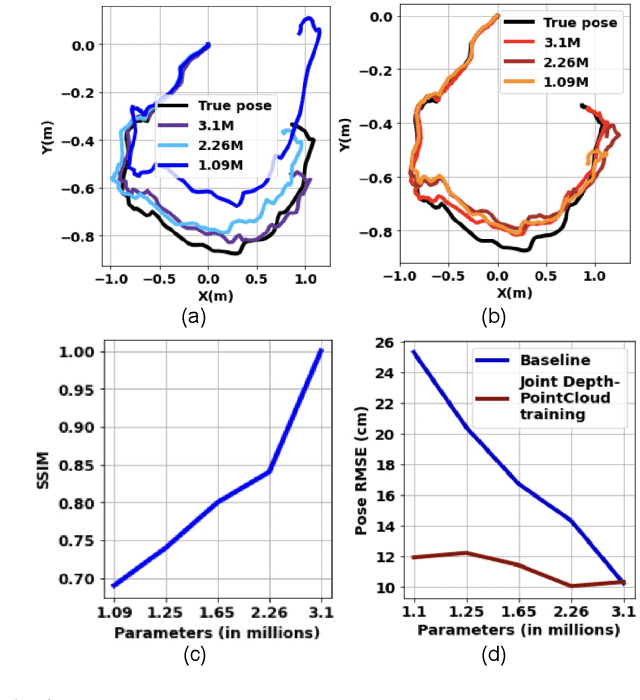
We present a novel monocular localization framework by jointly training deep learning-based depth prediction and Bayesian filtering-based pose reasoning. The proposed cross-modal framework significantly outperforms deep learning-only predictions with respect to model scalability and tolerance to environmental variations. Specifically, we show little-to-no degradation of pose accuracy even with extremely poor depth estimates from a lightweight depth predictor. Our framework also maintains high pose accuracy in extreme lighting variations compared to standard deep learning, even without explicit domain adaptation. By openly representing the map and intermediate feature maps (such as depth estimates), our framework also allows for faster updates and reusing intermediate predictions for other tasks, such as obstacle avoidance, resulting in much higher resource efficiency.