 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIME: Adapting a Single Neural Network for Multi-task Inference with Memory-efficient Dynamic Pruning
Paper and Code
Apr 11, 2022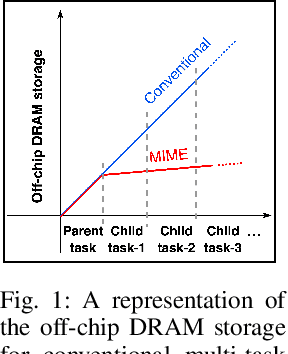
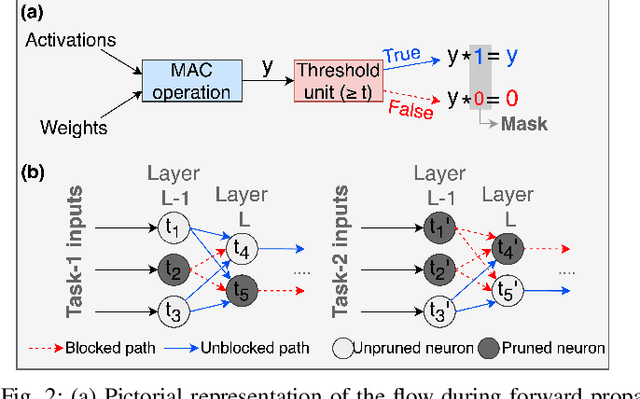
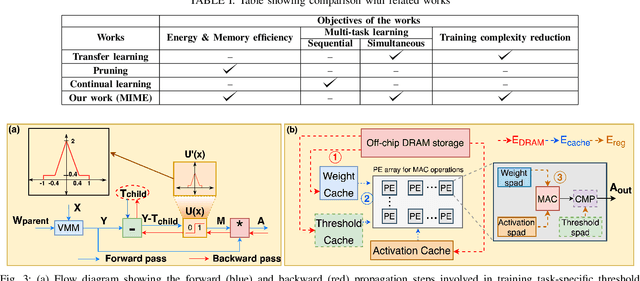
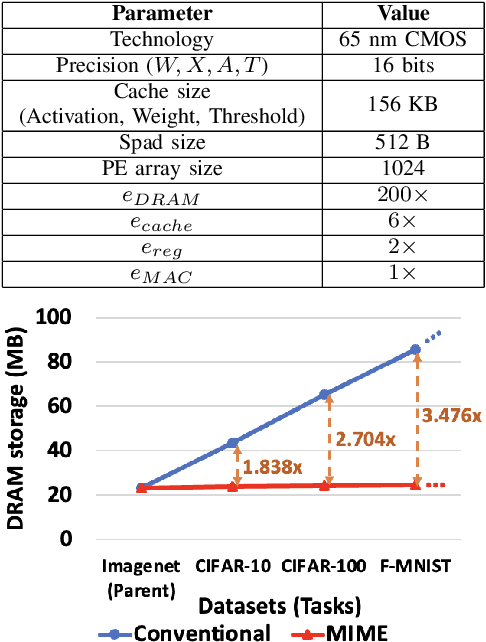
Recent years have seen a paradigm shift towards multi-task learning. This calls for memory and energy-efficient solutions for inference in a multi-task scenario. We propose an algorithm-hardware co-design approach called MIME. MIME reuses the weight parameters of a trained parent task and learns task-specific threshold parameters for inference on multiple child tasks. We find that MIME results in highly memory-efficient DRAM storage of neural-network parameters for multiple tasks compared to conventional multi-task inference. In addition, MIME results in input-dependent dynamic neuronal pruning, thereby enabling energy-efficient inference with higher throughput on a systolic-array hardware. Our experiments with benchmark datasets (child tasks)- CIFAR10, CIFAR100, and Fashion-MNIST, show that MIME achieves ~3.48x memory-efficiency and ~2.4-3.1x energy-savings compared to conventional multi-task inference in Pipelined task mode.