 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate ADCs for In-Memory Computing
Aug 11, 2024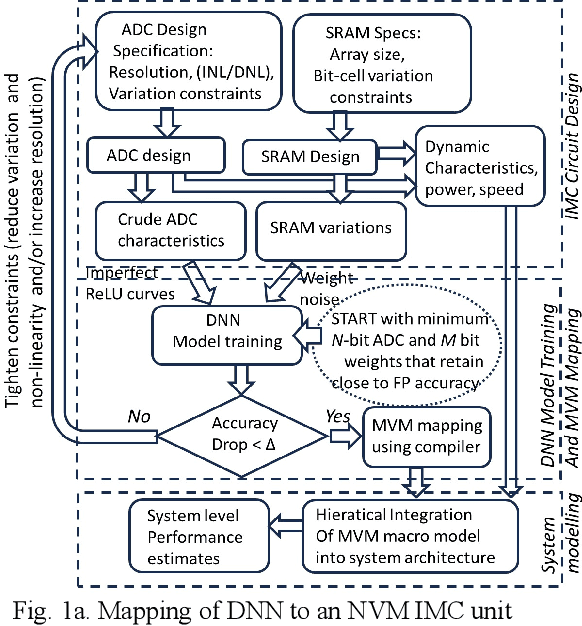
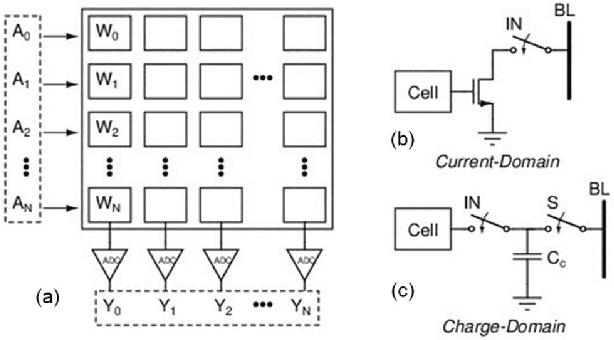
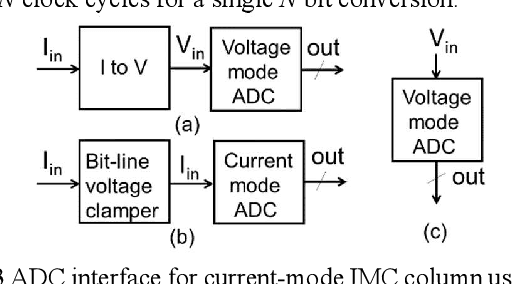
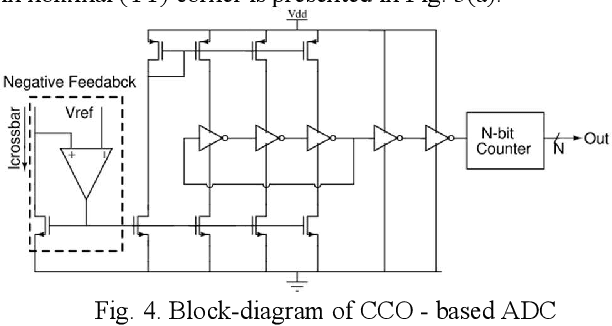
In memory computing (IMC) architectures for deep learning (DL) accelerators leverage energy-efficient and highly parallel matrix vector multiplication (MVM) operations, implemented directly in memory arrays. Such IMC designs have been explored based on CMOS as well as emerging non-volatile memory (NVM) technologies like RRAM. IMC architectures generally involve a large number of cores consisting of memory arrays, storing the trained weights of the DL model. Peripheral units like DACs and ADCs are also used for applying inputs and reading out the output values. Recently reported designs reveal that the ADCs required for reading out the MVM results, consume more than 85% of the total compute power and also dominate the area, thereby eschewing the benefits of the IMC scheme. Mitigation of imperfections in the ADCs, namely, non-linearity and variations, incur significant design overheads, due to dedicated calibration units. In this work we present peripheral aware design of IMC cores, to mitigate such overheads. It involves incorporating the non-idealities of ADCs in the training of the DL models, along with that of the memory units. The proposed approach applies equally well to both current mode as well as charge mode MVM operations demonstrated in recent years., and can significantly simplify the design of mixed-signal IMC units.