 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Rationalis? Measuring Bargaining Capabilities of AI Negotiators
Dec 15, 2025Bilateral negotiation is a complex, context-sensitive task in which human negotiators dynamically adjust anchors, pacing, and flexibility to exploit power asymmetries and informal cues. We introduce a unified mathematical framework for modeling concession dynamics based on a hyperbolic tangent curve, and propose two metrics burstiness tau and the Concession-Rigidity Index (CRI) to quantify the timing and rigidity of offer trajectories. We conduct a large-scale empirical comparison between human negotiators and four state-of-the-art large language models (LLMs) across natural-language and numeric-offers settings, with and without rich market context, as well as six controlled power-asymmetry scenarios. Our results reveal that, unlike humans who smoothly adapt to situations and infer the opponents position and strategies, LLMs systematically anchor at extremes of the possible agreement zone for negotiations and optimize for fixed points irrespective of leverage or context. Qualitative analysis further shows limited strategy diversity and occasional deceptive tactics used by LLMs. Moreover the ability of LLMs to negotiate does not improve with better models. These findings highlight fundamental limitations in current LLM negotiation capabilities and point to the need for models that better internalize opponent reasoning and context-dependent strategy.
The Geometry of Multilingual Language Models: An Equality Lens
May 13, 2023



Understanding the representations of different languages in multilingual language models is essential for comprehending their cross-lingual properties, predicting their performance on downstream tasks, and identifying any biases across languages. In our study, we analyze the geometry of three multilingual language models in Euclidean space and find that all languages are represented by unique geometries. Using a geometric separability index we find that although languages tend to be closer according to their linguistic family, they are almost separable with languages from other families. We also introduce a Cross-Lingual Similarity Index to measure the distance of languages with each other in the semantic space. Our findings indicate that the low-resource languages are not represented as good as high resource languages in any of the models
H-AES: Towards Automated Essay Scoring for Hindi
Feb 28, 2023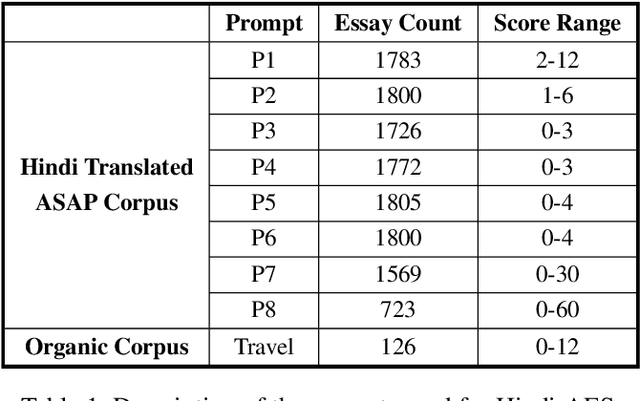
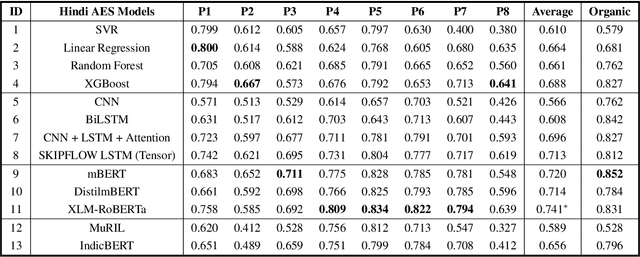

The use of Natural Language Processing (NLP) for Automated Essay Scoring (AES) has been well explored in the English language, with benchmark models exhibiting performance comparable to human scorers. However, AES in Hindi and other low-resource languages remains unexplored. In this study, we reproduce and compare state-of-the-art methods for AES in the Hindi domain. We employ classical feature-based Machine Learning (ML) and advanced end-to-end models, including LSTM Networks and Fine-Tuned Transformer Architecture, in our approach and derive results comparable to those in the English language domain. Hindi being a low-resource language, lacks a dedicated essay-scoring corpus. We train and evaluate our models using translated English essays and empirically measure their performance on our own small-scale, real-world Hindi corpus. We follow this up with an in-depth analysis discussing prompt-specific behavior of different language models implemented.