 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterChart: Benchmarking Visual Reasoning Across Decomposed and Distributed Chart Information
Aug 11, 2025We introduce InterChart, a diagnostic benchmark that evaluates how well vision-language models (VLMs) reason across multiple related charts, a task central to real-world applications such as scientific reporting, financial analysis, and public policy dashboards. Unlike prior benchmarks focusing on isolated, visually uniform charts, InterChart challenges models with diverse question types ranging from entity inference and trend correlation to numerical estimation and abstract multi-step reasoning grounded in 2-3 thematically or structurally related charts. We organize the benchmark into three tiers of increasing difficulty: (1) factual reasoning over individual charts, (2) integrative analysis across synthetically aligned chart sets, and (3) semantic inference over visually complex, real-world chart pairs. Our evaluation of state-of-the-art open and closed-source VLMs reveals consistent and steep accuracy declines as chart complexity increases. We find that models perform better when we decompose multi-entity charts into simpler visual units, underscoring their struggles with cross-chart integration. By exposing these systematic limitations, InterChart provides a rigorous framework for advancing multimodal reasoning in complex, multi-visual environments.
FlowVQA: Mapping Multimodal Logic in Visual Question Answering with Flowcharts
Jun 27, 2024Existing benchmarks for visual question answering lack in visual grounding and complexity, particularly in evaluating spatial reasoning skills. We introduce FlowVQA, a novel benchmark aimed at assessing the capabilities of visual question-answering multimodal language models in reasoning with flowcharts as visual contexts. FlowVQA comprises 2,272 carefully generated and human-verified flowchart images from three distinct content sources, along with 22,413 diverse question-answer pairs, to test a spectrum of reasoning tasks, including information localization, decision-making, and logical progression. We conduct a thorough baseline evaluation on a suite of both open-source and proprietary multimodal language models using various strategies, followed by an analysis of directional bias. The results underscore the benchmark's potential as a vital tool for advancing the field of multimodal modeling, providing a focused and challenging environment for enhancing model performance in visual and logical reasoning tasks.
H-AES: Towards Automated Essay Scoring for Hindi
Feb 28, 2023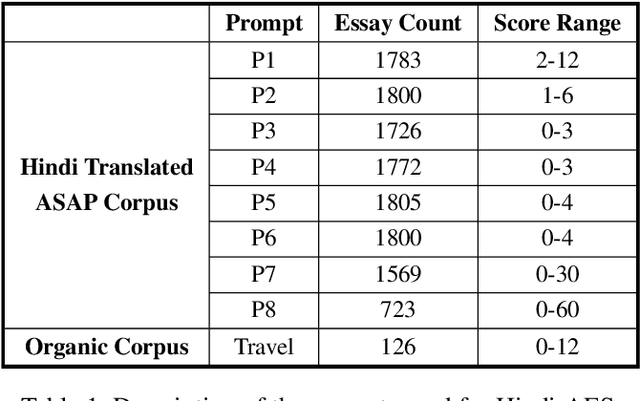
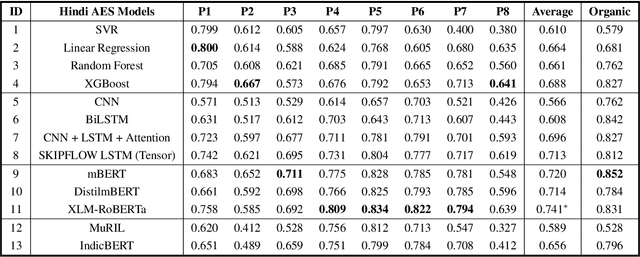

The use of Natural Language Processing (NLP) for Automated Essay Scoring (AES) has been well explored in the English language, with benchmark models exhibiting performance comparable to human scorers. However, AES in Hindi and other low-resource languages remains unexplored. In this study, we reproduce and compare state-of-the-art methods for AES in the Hindi domain. We employ classical feature-based Machine Learning (ML) and advanced end-to-end models, including LSTM Networks and Fine-Tuned Transformer Architecture, in our approach and derive results comparable to those in the English language domain. Hindi being a low-resource language, lacks a dedicated essay-scoring corpus. We train and evaluate our models using translated English essays and empirically measure their performance on our own small-scale, real-world Hindi corpus. We follow this up with an in-depth analysis discussing prompt-specific behavior of different language models implemented.