 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much User Context Do We Need? Privacy by Design in Mental Health NLP Application
Paper and Code
Sep 05, 2022
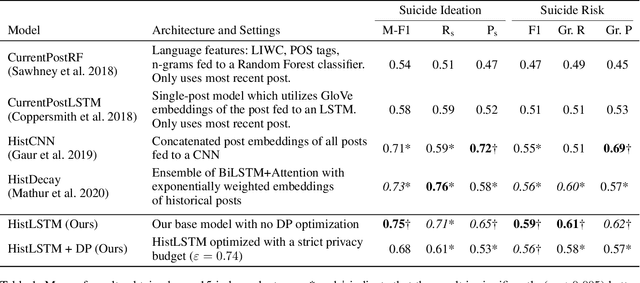
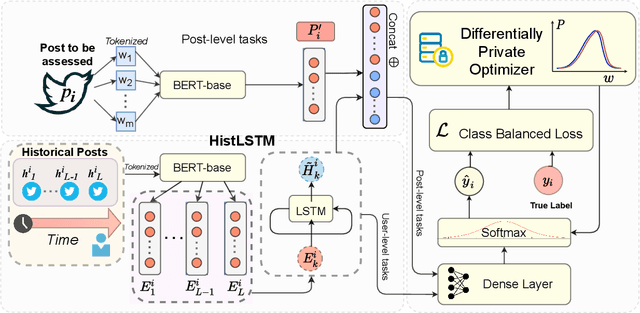
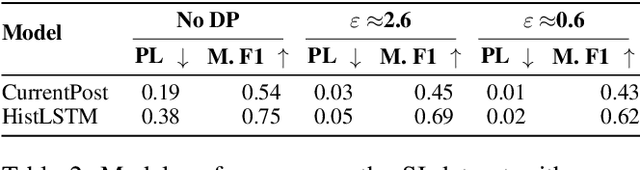
Clinical NLP tasks such as mental health assessment from text, must take social constraints into account - the performance maximization must be constrained by the utmost importance of guaranteeing privacy of user data. Consumer protection regulations, such as GDPR, generally handle privacy by restricting data availability, such as requiring to limit user data to 'what is necessary' for a given purpose. In this work, we reason that providing stricter formal privacy guarantees, while increasing the volume of user data in the model, in most cases increases benefit for all parties involved, especially for the user. We demonstrate our arguments on two existing suicide risk assessment datasets of Twitter and Reddit posts. We present the first analysis juxtaposing user history length and differential privacy budgets and elaborate how modeling additional user context enables utility preservation while maintaining acceptable user privacy guarantees.