 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn designing light-weight object trackers through network pruning: Use CNNs or transformers?
Nov 24, 2022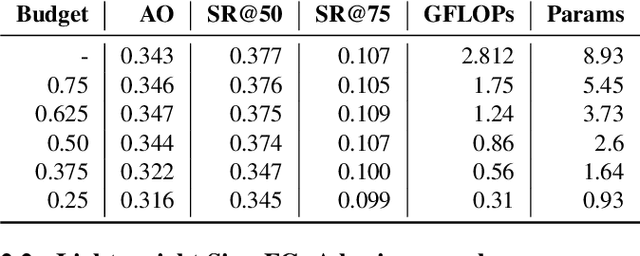
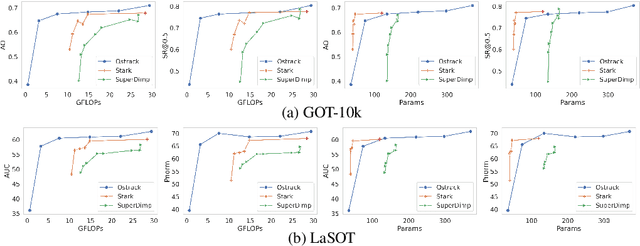


Object trackers deployed on low-power devices need to be light-weight, however, most of the current state-of-the-art (SOTA) methods rely on using compute-heavy backbones built using CNNs or transformers. Large sizes of such models do not allow their deployment in low-power conditions and designing compressed variants of large tracking models is of great importance. This paper demonstrates how highly compressed light-weight object trackers can be designed using neural architectural pruning of large CNN and transformer based trackers. Further, a comparative study on architectural choices best suited to design light-weight trackers is provided. A comparison between SOTA trackers using CNNs, transformers as well as the combination of the two is presented to study their stability at various compression ratios. Finally results for extreme pruning scenarios going as low as 1% in some cases are shown to study the limits of network pruning in object tracking. This work provides deeper insights into designing highly efficient trackers from existing SOTA methods.
GPTs at Factify 2022: Prompt Aided Fact-Verification
Jun 29, 2022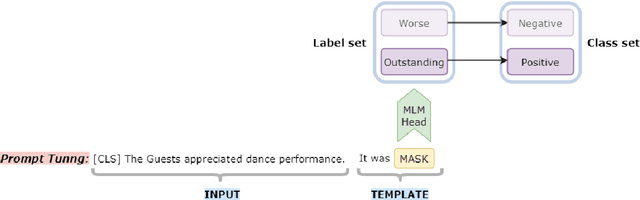


One of the most pressing societal issues is the fight against false news. The false claims, as difficult as they are to expose, create a lot of damage. To tackle the problem, fact verification becomes crucial and thus has been a topic of interest among diverse research communities. Using only the textual form of data we propose our solution to the problem and achieve competitive results with other approaches. We present our solution based on two approaches - PLM (pre-trained language model) based method and Prompt based method. The PLM-based approach uses the traditional supervised learning, where the model is trained to take 'x' as input and output prediction 'y' as P(y|x). Whereas, Prompt-based learning reflects the idea to design input to fit the model such that the original objective may be re-framed as a problem of (masked) language modeling. We may further stimulate the rich knowledge provided by PLMs to better serve downstream tasks by employing extra prompts to fine-tune PLMs. Our experiments showed that the proposed method performs better than just fine-tuning PLMs. We achieved an F1 score of 0.6946 on the FACTIFY dataset and a 7th position on the competition leader-board.