 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Pre-trained Representation Space: On Effectiveness of Prefix-tuning for Large Multi-modal Models
Oct 29, 2024

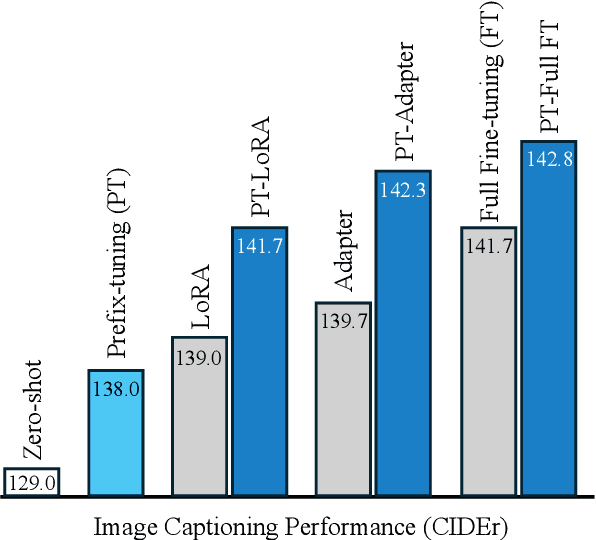

Recently, we have observed that Large Multi-modal Models (LMMs) are revolutionizing the way machines interact with the world, unlocking new possibilities across various multi-modal applications. To adapt LMMs for downstream tasks, parameter-efficient fine-tuning (PEFT) which only trains additional prefix tokens or modules, has gained popularity. Nevertheless, there has been little analysis of how PEFT works in LMMs. In this paper, we delve into the strengths and weaknesses of each tuning strategy, shifting the focus from the efficiency typically associated with these approaches. We first discover that model parameter tuning methods such as LoRA and Adapters distort the feature representation space learned during pre-training and limit the full utilization of pre-trained knowledge. We also demonstrate that prefix-tuning excels at preserving the representation space, despite its lower performance on downstream tasks. These findings suggest a simple two-step PEFT strategy called Prefix-Tuned PEFT (PT-PEFT), which successively performs prefix-tuning and then PEFT (i.e., Adapter, LoRA), combines the benefits of both. Experimental results show that PT-PEFT not only improves performance in image captioning and visual question answering compared to vanilla PEFT methods but also helps preserve the representation space of the four pre-trained models.
Depth-Relative Self Attention for Monocular Depth Estimation
Apr 25, 2023Monocular depth estimation is very challenging because clues to the exact depth are incomplete in a single RGB image. To overcome the limitation, deep neural networks rely on various visual hints such as size, shade, and texture extracted from RGB information. However, we observe that if such hints are overly exploited, the network can be biased on RGB information without considering the comprehensive view. We propose a novel depth estimation model named RElative Depth Transformer (RED-T) that uses relative depth as guidance in self-attention. Specifically, the model assigns high attention weights to pixels of close depth and low attention weights to pixels of distant depth. As a result, the features of similar depth can become more likely to each other and thus less prone to misused visual hints. We show that the proposed model achieves competitive results in monocular depth estimation benchmarks and is less biased to RGB information. In addition, we propose a novel monocular depth estimation benchmark that limits the observable depth range during training in order to evaluate the robustness of the model for unseen depths.
Feasibility Study of Multi-Site Split Learning for Privacy-Preserving Medical Systems under Data Imbalance Constraints in COVID-19, X-Ray, and Cholesterol Dataset
Feb 21, 2022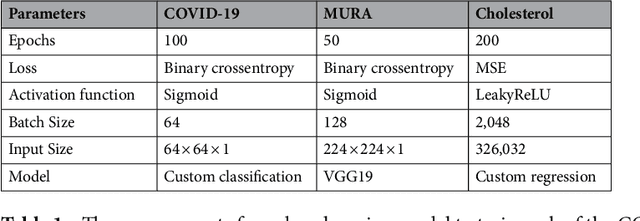



It seems as though progressively more people are in the race to upload content, data, and information online; and hospitals haven't neglected this trend either. Hospitals are now at the forefront for multi-site medical data sharing to provide groundbreaking advancements in the way health records are shared and patients are diagnosed. Sharing of medical data is essential in modern medical research. Yet, as with all data sharing technology, the challenge is to balance improved treatment with protecting patient's personal information. This paper provides a novel split learning algorithm coined the term, "multi-site split learning", which enables a secure transfer of medical data between multiple hospitals without fear of exposing personal data contained in patient records. It also explores the effects of varying the number of end-systems and the ratio of data-imbalance on the deep learning performance. A guideline for the most optimal configuration of split learning that ensures privacy of patient data whilst achieving performance is empirically given. We argue the benefits of our multi-site split learning algorithm, especially regarding the privacy preserving factor, using CT scans of COVID-19 patients, X-ray bone scans, and cholesterol level medical data.
Spatio-Temporal Split Learning for Privacy-Preserving Medical Platforms: Case Studies with COVID-19 CT, X-Ray, and Cholesterol Data
Aug 20, 2021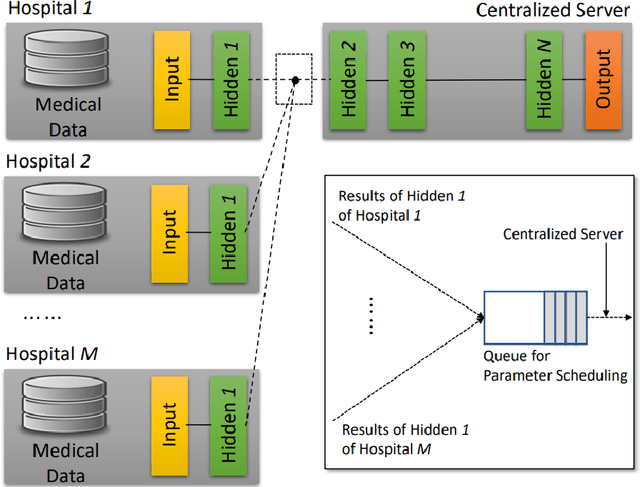

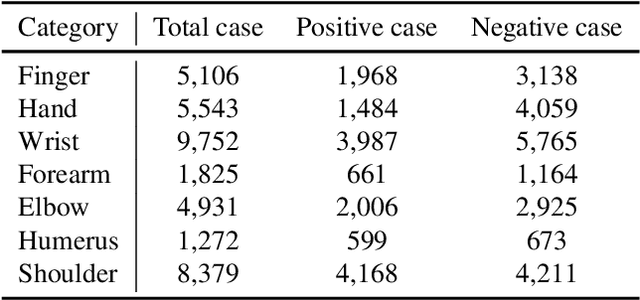
Machine learning requires a large volume of sample data, especially when it is used in high-accuracy medical applications. However, patient records are one of the most sensitive private information that is not usually shared among institutes. This paper presents spatio-temporal split learning, a distributed deep neural network framework, which is a turning point in allowing collaboration among privacy-sensitive organizations. Our spatio-temporal split learning presents how distributed machine learning can be efficiently conducted with minimal privacy concerns. The proposed split learning consists of a number of clients and a centralized server. Each client has only has one hidden layer, which acts as the privacy-preserving layer, and the centralized server comprises the other hidden layers and the output layer. Since the centralized server does not need to access the training data and trains the deep neural network with parameters received from the privacy-preserving layer, privacy of original data is guaranteed. We have coined the term, spatio-temporal split learning, as multiple clients are spatially distributed to cover diverse datasets from different participants, and we can temporally split the learning process, detaching the privacy preserving layer from the rest of the learning process to minimize privacy breaches. This paper shows how we can analyze the medical data whilst ensuring privacy using our proposed multi-site spatio-temporal split learning algorithm on Coronavirus Disease-19 (COVID-19) chest Computed Tomography (CT) scans, MUsculoskeletal RAdiographs (MURA) X-ray images, and cholesterol levels.
Visualization of Deep Reinforcement Autonomous Aerial Mobility Learning Simulations
Feb 14, 2021
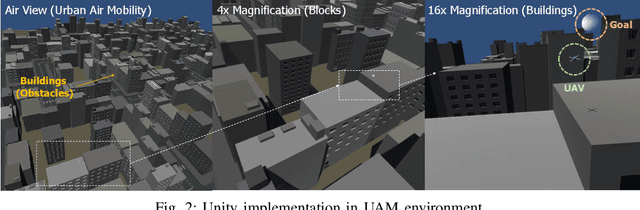
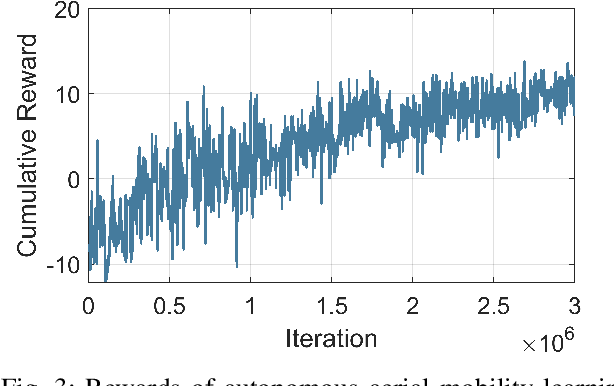
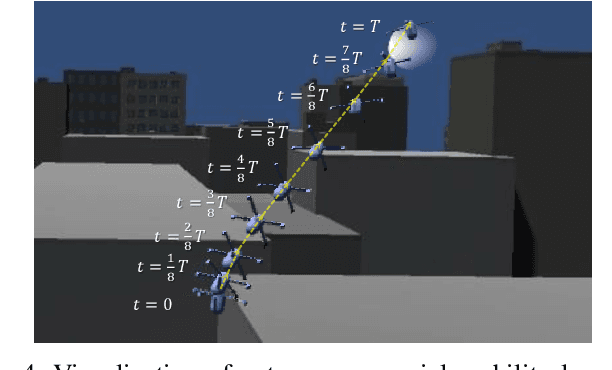
This demo abstract presents the visualization of deep reinforcement learning (DRL)-based autonomous aerial mobility simulations. In order to implement the software, Unity-RL is used and additional buildings are introduced for urban environment. On top of the implementation, DRL algorithms are used and we confirm it works well in terms of trajectory and 3D visualization.