 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Prediction as Implicit Classification to Identify LLM-Generated Text
Nov 15, 2023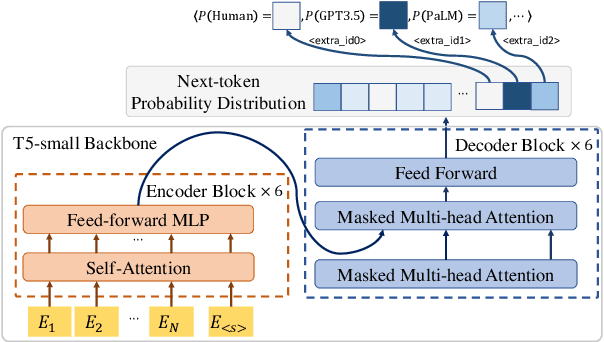



This paper introduces a novel approach for identifying the possible large language models (LLMs) involved in text generation. Instead of adding an additional classification layer to a base LM, we reframe the classification task as a next-token prediction task and directly fine-tune the base LM to perform it. We utilize the Text-to-Text Transfer Transformer (T5) model as the backbone for our experiments. We compared our approach to the more direct approach of utilizing hidden states for classification. Evaluation shows the exceptional performance of our method in the text classification task, highlighting its simplicity and efficiency. Furthermore, interpretability studies on the features extracted by our model reveal its ability to differentiate distinctive writing styles among various LLMs even in the absence of an explicit classifier. We also collected a dataset named OpenLLMText, containing approximately 340k text samples from human and LLMs, including GPT3.5, PaLM, LLaMA, and GPT2.
Listener Model for the PhotoBook Referential Game with CLIPScores as Implicit Reference Chain
Jun 16, 2023



PhotoBook is a collaborative dialogue game where two players receive private, partially-overlapping sets of images and resolve which images they have in common. It presents machines with a great challenge to learn how people build common ground around multimodal context to communicate effectively. Methods developed in the literature, however, cannot be deployed to real gameplay since they only tackle some subtasks of the game, and they require additional reference chains inputs, whose extraction process is imperfect. Therefore, we propose a reference chain-free listener model that directly addresses the game's predictive task, i.e., deciding whether an image is shared with partner. Our DeBERTa-based listener model reads the full dialogue, and utilizes CLIPScore features to assess utterance-image relevance. We achieve >77% accuracy on unseen sets of images/game themes, outperforming baseline by >17 points.
GPT-Sentinel: Distinguishing Human and ChatGPT Generated Content
May 17, 2023This paper presents a novel approach for detecting ChatGPT-generated vs. human-written text using language models. To this end, we first collected and released a pre-processed dataset named OpenGPTText, which consists of rephrased content generated using ChatGPT. We then designed, implemented, and trained two different models for text classification, using Robustly Optimized BERT Pretraining Approach (RoBERTa) and Text-to-Text Transfer Transformer (T5), respectively. Our models achieved remarkable results, with an accuracy of over 97% on the test dataset, as evaluated through various metrics. Furthermore, we conducted an interpretability study to showcase our model's ability to extract and differentiate key features between human-written and ChatGPT-generated text. Our findings provide important insights into the effective use of language models to detect generated text.