 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTitaNet: Neural Model for speaker representation with 1D Depth-wise separable convolutions and global context
Paper and Code


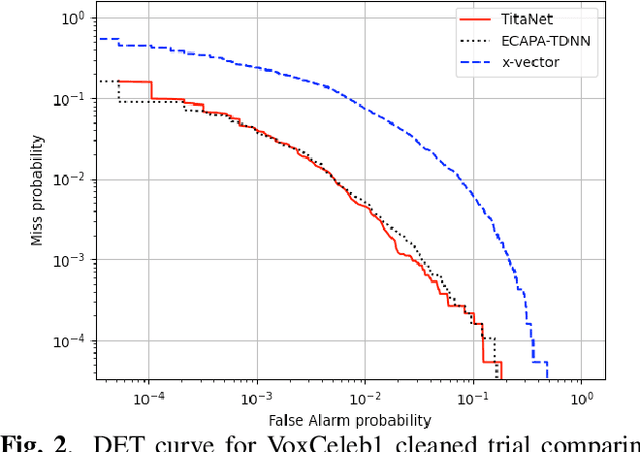

In this paper, we propose TitaNet, a novel neural network architecture for extracting speaker representations. We employ 1D depth-wise separable convolutions with Squeeze-and-Excitation (SE) layers with global context followed by channel attention based statistics pooling layer to map variable-length utterances to a fixed-length embedding (t-vector). TitaNet is a scalable architecture and achieves state-of-the-art performance on speaker verification task with an equal error rate (EER) of 0.68% on the VoxCeleb1 trial file and also on speaker diarization tasks with diarization error rate (DER) of 1.73% on AMI-MixHeadset, 1.99% on AMI-Lapel and 1.11% on CH109. Furthermore, we investigate various sizes of TitaNet and present a light TitaNet-S model with only 6M parameters that achieve near state-of-the-art results in diarization tasks.