 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Cognitive State Classification from Speech with Multi-View Pseudo-Labeling
Paper and Code
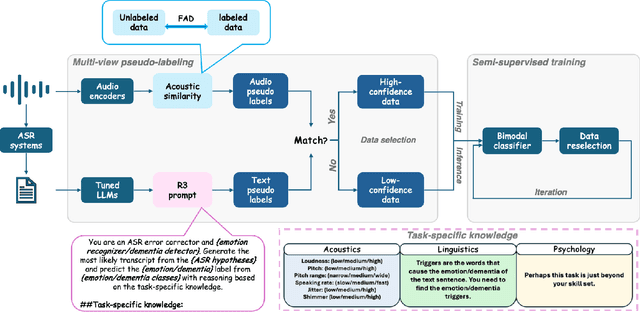
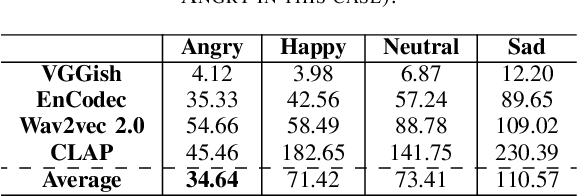
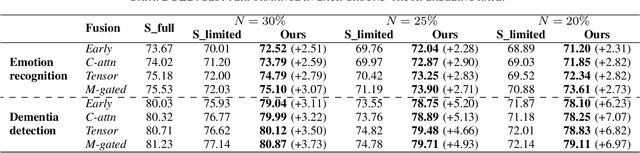
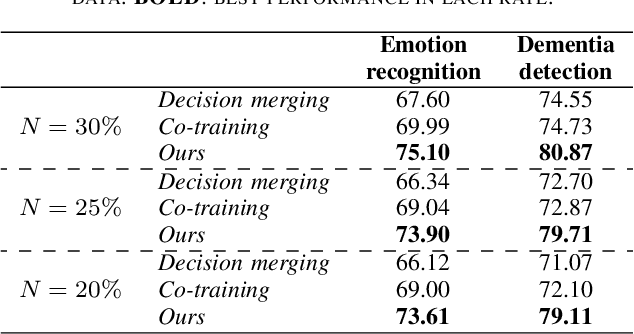
The lack of labeled data is a common challenge in speech classification tasks, particularly those requiring extensive subjective assessment, such as cognitive state classification. In this work, we propose a Semi-Supervised Learning (SSL) framework, introducing a novel multi-view pseudo-labeling method that leverages both acoustic and linguistic characteristics to select the most confident data for training the classification model. Acoustically, unlabeled data are compared to labeled data using the Frechet audio distance, calculated from embeddings generated by multiple audio encoders. Linguistically, large language models are prompted to revise automatic speech recognition transcriptions and predict labels based on our proposed task-specific knowledge. High-confidence data are identified when pseudo-labels from both sources align, while mismatches are treated as low-confidence data. A bimodal classifier is then trained to iteratively label the low-confidence data until a predefined criterion is met. We evaluate our SSL framework on emotion recognition and dementia detection tasks. Experimental results demonstrate that our method achieves competitive performance compared to fully supervised learning using only 30% of the labeled data and significantly outperforms two selected baselines.