 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Apr 15, 2026We introduce HY-World 2.0, a multi-modal world model framework that advances our prior project HY-World 1.0. HY-World 2.0 accommodates diverse input modalities, including text prompts, single-view images, multi-view images, and videos, and produces 3D world representations. With text or single-view image inputs, the model performs world generation, synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes. This is achieved through a four-stage method: a) Panorama Generation with HY-Pano 2.0, b) Trajectory Planning with WorldNav, c) World Expansion with WorldStereo 2.0, and d) World Composition with WorldMirror 2.0. Specifically, we introduce key innovations to enhance panorama fidelity, enable 3D scene understanding and planning, and upgrade WorldStereo, our keyframe-based view generation model with consistent memory. We also upgrade WorldMirror, a feed-forward model for universal 3D prediction, by refining model architecture and learning strategy, enabling world reconstruction from multi-view images or videos. Also, we introduce WorldLens, a high-performance 3DGS rendering platform featuring a flexible engine-agnostic architecture, automatic IBL lighting, efficient collision detection, and training-rendering co-design, enabling interactive exploration of 3D worlds with character support. Extensive experiments demonstrate that HY-World 2.0 achieves state-of-the-art performance on several benchmarks among open-source approaches, delivering results comparable to the closed-source model Marble. We release all model weights, code, and technical details to facilitate reproducibility and support further research on 3D world models.
CTCal: Rethinking Text-to-Image Diffusion Models via Cross-Timestep Self-Calibration
Mar 21, 2026Recent advancements in text-to-image synthesis have been largely propelled by diffusion-based models, yet achieving precise alignment between text prompts and generated images remains a persistent challenge. We find that this difficulty arises primarily from the limitations of conventional diffusion loss, which provides only implicit supervision for modeling fine-grained text-image correspondence. In this paper, we introduce Cross-Timestep Self-Calibration (CTCal), founded on the supporting observation that establishing accurate text-image alignment within diffusion models becomes progressively more difficult as the timestep increases. CTCal leverages the reliable text-image alignment (i.e., cross-attention maps) formed at smaller timesteps with less noise to calibrate the representation learning at larger timesteps with more noise, thereby providing explicit supervision during training. We further propose a timestep-aware adaptive weighting to achieve a harmonious integration of CTCal and diffusion loss. CTCal is model-agnostic and can be seamlessly integrated into existing text-to-image diffusion models, encompassing both diffusion-based (e.g., SD 2.1) and flow-based approaches (e.g., SD 3). Extensive experiments on T2I-Compbench++ and GenEval benchmarks demonstrate the effectiveness and generalizability of the proposed CTCal. Our code is available at https://github.com/xiefan-guo/ctcal.
WorldCompass: Reinforcement Learning for Long-Horizon World Models
Feb 09, 2026This work presents WorldCompass, a novel Reinforcement Learning (RL) post-training framework for the long-horizon, interactive video-based world models, enabling them to explore the world more accurately and consistently based on interaction signals. To effectively "steer" the world model's exploration, we introduce three core innovations tailored to the autoregressive video generation paradigm: 1) Clip-level rollout Strategy: We generate and evaluate multiple samples at a single target clip, which significantly boosts rollout efficiency and provides fine-grained reward signals. 2) Complementary Reward Functions: We design reward functions for both interaction-following accuracy and visual quality, which provide direct supervision and effectively suppress reward-hacking behaviors. 3) Efficient RL Algorithm: We employ the negative-aware fine-tuning strategy coupled with various efficiency optimizations to efficiently and effectively enhance model capacity. Evaluations on the SoTA open-source world model, WorldPlay, demonstrate that WorldCompass significantly improves interaction accuracy and visual fidelity across various scenarios.
Pathwise Test-Time Correction for Autoregressive Long Video Generation
Feb 05, 2026Distilled autoregressive diffusion models facilitate real-time short video synthesis but suffer from severe error accumulation during long-sequence generation. While existing Test-Time Optimization (TTO) methods prove effective for images or short clips, we identify that they fail to mitigate drift in extended sequences due to unstable reward landscapes and the hypersensitivity of distilled parameters. To overcome these limitations, we introduce Test-Time Correction (TTC), a training-free alternative. Specifically, TTC utilizes the initial frame as a stable reference anchor to calibrate intermediate stochastic states along the sampling trajectory. Extensive experiments demonstrate that our method seamlessly integrates with various distilled models, extending generation lengths with negligible overhead while matching the quality of resource-intensive training-based methods on 30-second benchmarks.
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Dec 16, 2025This paper presents WorldPlay, a streaming video diffusion model that enables real-time, interactive world modeling with long-term geometric consistency, resolving the trade-off between speed and memory that limits current methods. WorldPlay draws power from three key innovations. 1) We use a Dual Action Representation to enable robust action control in response to the user's keyboard and mouse inputs. 2) To enforce long-term consistency, our Reconstituted Context Memory dynamically rebuilds context from past frames and uses temporal reframing to keep geometrically important but long-past frames accessible, effectively alleviating memory attenuation. 3) We also propose Context Forcing, a novel distillation method designed for memory-aware model. Aligning memory context between the teacher and student preserves the student's capacity to use long-range information, enabling real-time speeds while preventing error drift. Taken together, WorldPlay generates long-horizon streaming 720p video at 24 FPS with superior consistency, comparing favorably with existing techniques and showing strong generalization across diverse scenes. Project page and online demo can be found: https://3d-models.hunyuan.tencent.com/world/ and https://3d.hunyuan.tencent.com/sceneTo3D.
GenHOI: Generalizing Text-driven 4D Human-Object Interaction Synthesis for Unseen Objects
Jun 18, 2025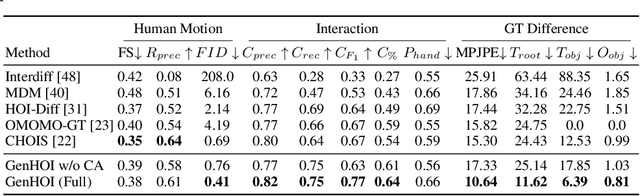
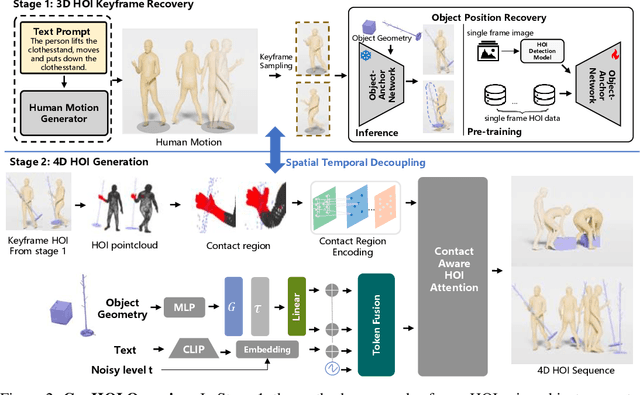
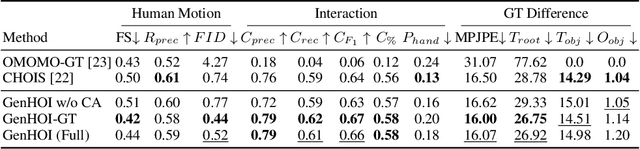
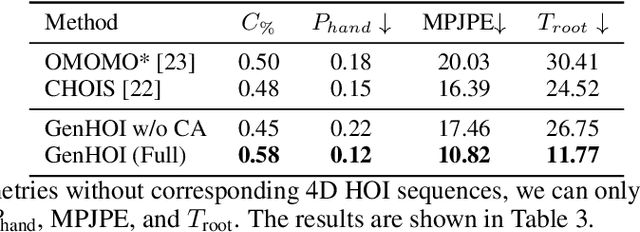
While diffusion models and large-scale motion datasets have advanced text-driven human motion synthesis, extending these advances to 4D human-object interaction (HOI) remains challenging, mainly due to the limited availability of large-scale 4D HOI datasets. In our study, we introduce GenHOI, a novel two-stage framework aimed at achieving two key objectives: 1) generalization to unseen objects and 2) the synthesis of high-fidelity 4D HOI sequences. In the initial stage of our framework, we employ an Object-AnchorNet to reconstruct sparse 3D HOI keyframes for unseen objects, learning solely from 3D HOI datasets, thereby mitigating the dependence on large-scale 4D HOI datasets. Subsequently, we introduce a Contact-Aware Diffusion Model (ContactDM) in the second stage to seamlessly interpolate sparse 3D HOI keyframes into densely temporally coherent 4D HOI sequences. To enhance the quality of generated 4D HOI sequences, we propose a novel Contact-Aware Encoder within ContactDM to extract human-object contact patterns and a novel Contact-Aware HOI Attention to effectively integrate the contact signals into diffusion models. Experimental results show that we achieve state-of-the-art results on the publicly available OMOMO and 3D-FUTURE datasets, demonstrating strong generalization abilities to unseen objects, while enabling high-fidelity 4D HOI generation.
Weakly Supervised Temporal Sentence Grounding via Positive Sample Mining
May 10, 2025The task of weakly supervised temporal sentence grounding (WSTSG) aims to detect temporal intervals corresponding to a language description from untrimmed videos with only video-level video-language correspondence. For an anchor sample, most existing approaches generate negative samples either from other videos or within the same video for contrastive learning. However, some training samples are highly similar to the anchor sample, directly regarding them as negative samples leads to difficulties for optimization and ignores the correlations between these similar samples and the anchor sample. To address this, we propose Positive Sample Mining (PSM), a novel framework that mines positive samples from the training set to provide more discriminative supervision. Specifically, for a given anchor sample, we partition the remaining training set into semantically similar and dissimilar subsets based on the similarity of their text queries. To effectively leverage these correlations, we introduce a PSM-guided contrastive loss to ensure that the anchor proposal is closer to similar samples and further from dissimilar ones. Additionally, we design a PSM-guided rank loss to ensure that similar samples are closer to the anchor proposal than to the negative intra-video proposal, aiming to distinguish the anchor proposal and the negative intra-video proposal. Experiments on the WSTSG and grounded VideoQA tasks demonstrate the effectiveness and superiority of our method.
AccVideo: Accelerating Video Diffusion Model with Synthetic Dataset
Mar 25, 2025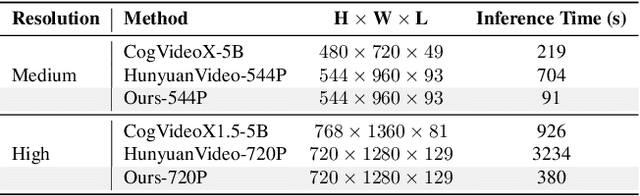
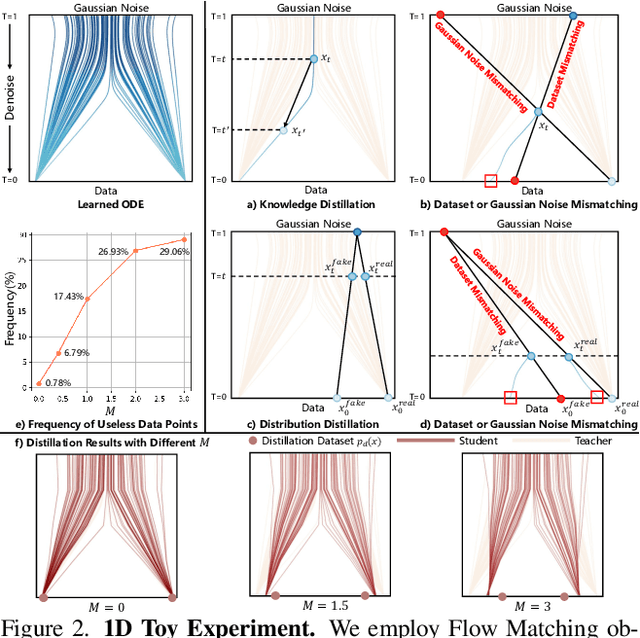

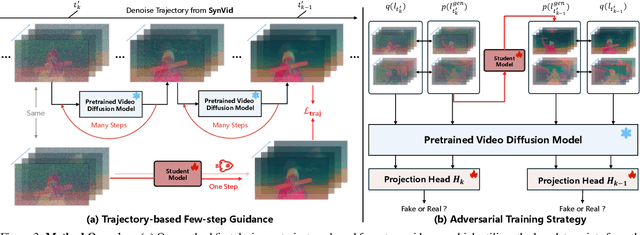
Diffusion models have achieved remarkable progress in the field of video generation. However, their iterative denoising nature requires a large number of inference steps to generate a video, which is slow and computationally expensive. In this paper, we begin with a detailed analysis of the challenges present in existing diffusion distillation methods and propose a novel efficient method, namely AccVideo, to reduce the inference steps for accelerating video diffusion models with synthetic dataset. We leverage the pretrained video diffusion model to generate multiple valid denoising trajectories as our synthetic dataset, which eliminates the use of useless data points during distillation. Based on the synthetic dataset, we design a trajectory-based few-step guidance that utilizes key data points from the denoising trajectories to learn the noise-to-video mapping, enabling video generation in fewer steps. Furthermore, since the synthetic dataset captures the data distribution at each diffusion timestep, we introduce an adversarial training strategy to align the output distribution of the student model with that of our synthetic dataset, thereby enhancing the video quality. Extensive experiments demonstrate that our model achieves 8.5x improvements in generation speed compared to the teacher model while maintaining comparable performance. Compared to previous accelerating methods, our approach is capable of generating videos with higher quality and resolution, i.e., 5-seconds, 720x1280, 24fps.
4Diffusion: Multi-view Video Diffusion Model for 4D Generation
May 31, 2024



Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
ImFace++: A Sophisticated Nonlinear 3D Morphable Face Model with Implicit Neural Representations
Dec 07, 2023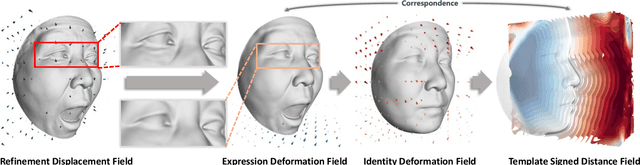
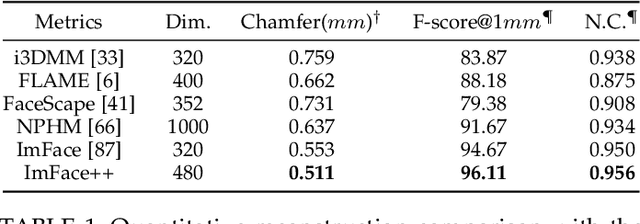
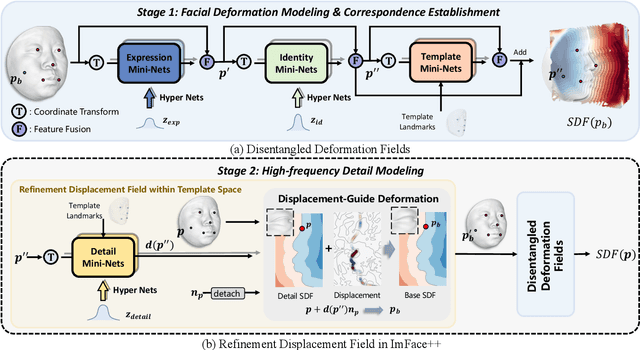
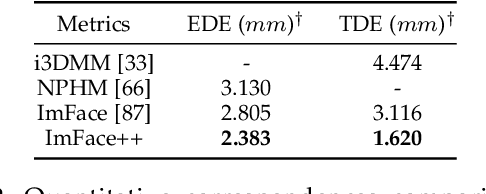
Accurate representations of 3D faces are of paramount importance in various computer vision and graphics applications. However, the challenges persist due to the limitations imposed by data discretization and model linearity, which hinder the precise capture of identity and expression clues in current studies. This paper presents a novel 3D morphable face model, named ImFace++, to learn a sophisticated and continuous space with implicit neural representations. ImFace++ first constructs two explicitly disentangled deformation fields to model complex shapes associated with identities and expressions, respectively, which simultaneously facilitate the automatic learning of correspondences across diverse facial shapes. To capture more sophisticated facial details, a refinement displacement field within the template space is further incorporated, enabling a fine-grained learning of individual-specific facial details. Furthermore, a Neural Blend-Field is designed to reinforce the representation capabilities through adaptive blending of an array of local fields. In addition to ImFace++, we have devised an improved learning strategy to extend expression embeddings, allowing for a broader range of expression variations. Comprehensive qualitative and quantitative evaluations demonstrate that ImFace++ significantly advances the state-of-the-art in terms of both face reconstruction fidelity and correspondence accuracy.