 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Wikipedia into Augmented Data for Query-Focused Summarization
Paper and Code
Nov 08, 2019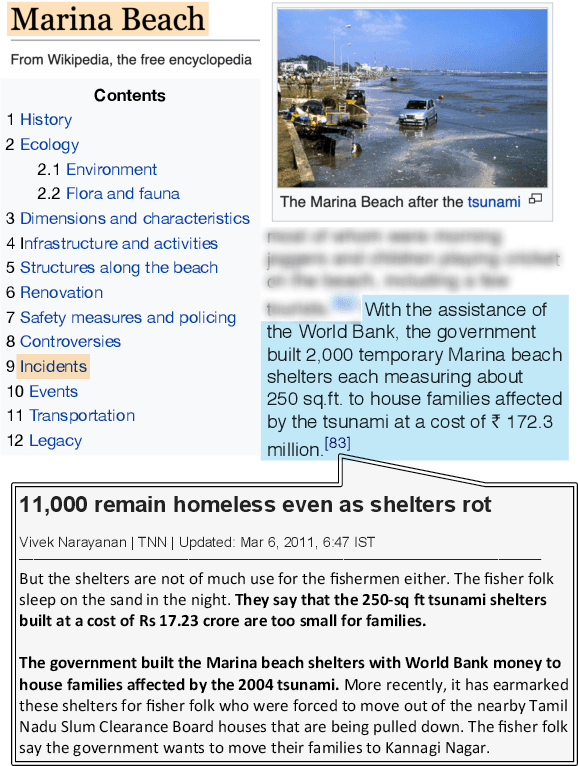
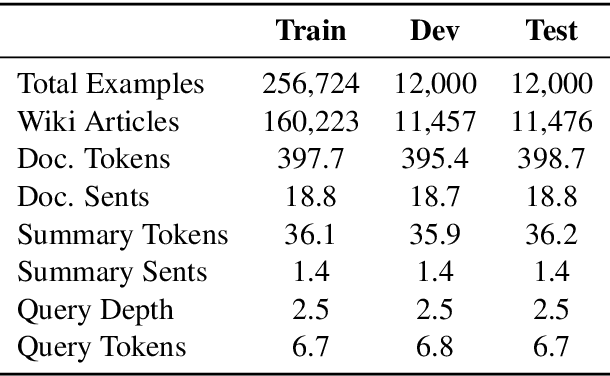
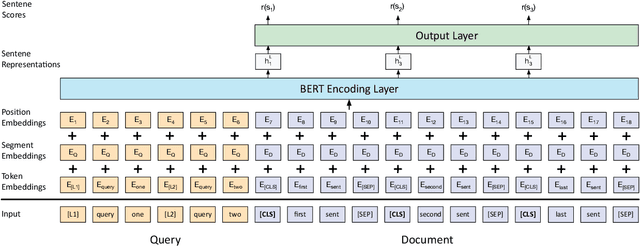

The manual construction of a query-focused summarization corpus is costly and timeconsuming. The limited size of existing datasets renders training data-driven summarization models challenging. In this paper, we use Wikipedia to automatically collect a large query-focused summarization dataset (named as WIKIREF) of more than 280,000 examples, which can serve as a means of data augmentation. Moreover, we develop a query-focused summarization model based on BERT to extract summaries from the documents. Experimental results on three DUC benchmarks show that the model pre-trained on WIKIREF has already achieved reasonable performance. After fine-tuning on the specific datasets, the model with data augmentation outperforms the state of the art on the benchmarks.