 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs a Green Screen Really Necessary for Real-Time Portrait Matting?
Nov 29, 2020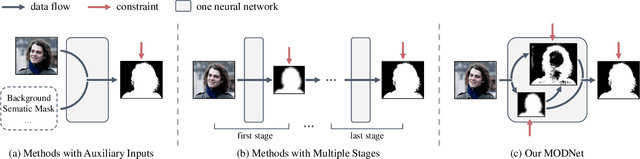
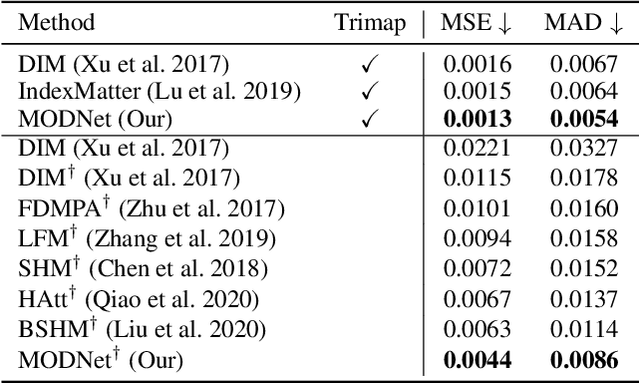
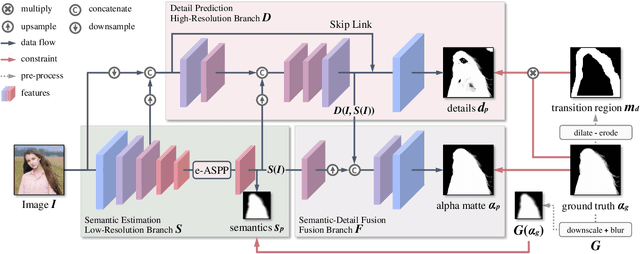
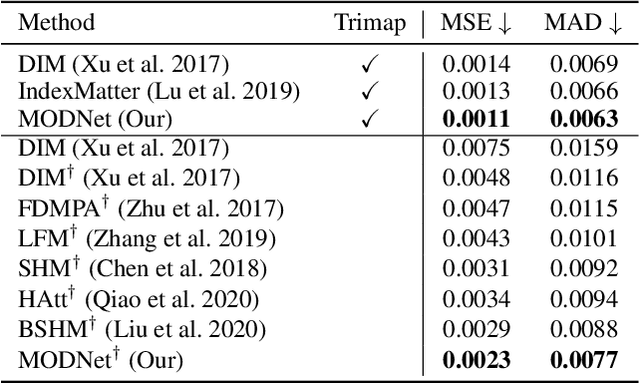
For portrait matting without the green screen, existing works either require auxiliary inputs that are costly to obtain or use multiple models that are computationally expensive. Consequently, they are unavailable in real-time applications. In contrast, we present a light-weight matting objective decomposition network (MODNet), which can process portrait matting from a single input image in real time. The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints. Moreover, since trimap-free methods usually suffer from the domain shift problem in practice, we introduce (1) a self-supervised strategy based on sub-objectives consistency to adapt MODNet to real-world data and (2) a one-frame delay trick to smooth the results when applying MODNet to portrait video sequence. MODNet is easy to be trained in an end-to-end style. It is much faster than contemporaneous matting methods and runs at 63 frames per second. On a carefully designed portrait matting benchmark newly proposed in this work, MODNet greatly outperforms prior trimap-free methods. More importantly, our method achieves remarkable results in daily photos and videos. Now, do you really need a green screen for real-time portrait matting?