 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Temporal Link Prediction
Apr 15, 2025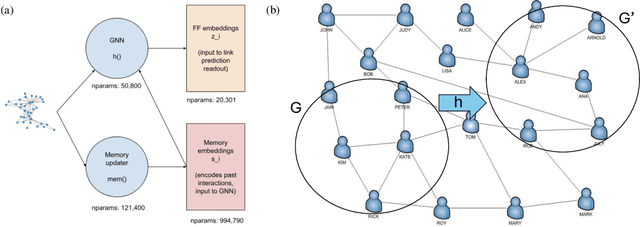
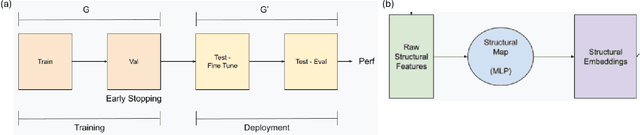
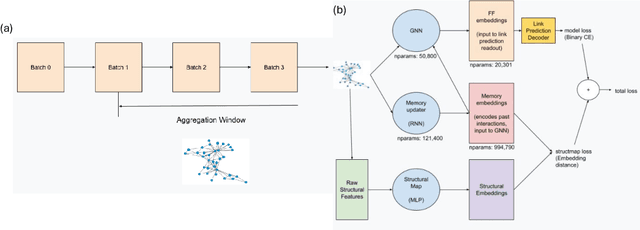
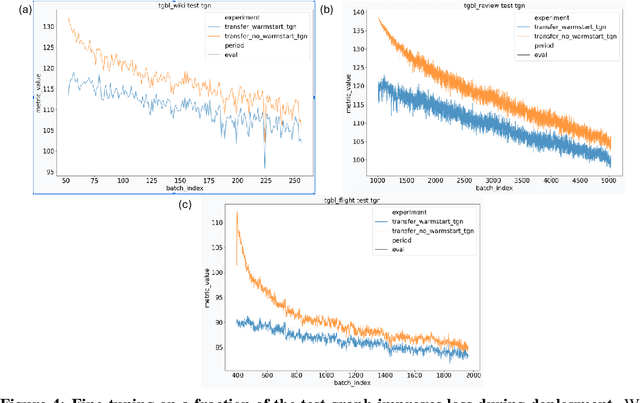
Link prediction on graphs has applications spanning from recommender systems to drug discovery. Temporal link prediction (TLP) refers to predicting future links in a temporally evolving graph and adds additional complexity related to the dynamic nature of graphs. State-of-the-art TLP models incorporate memory modules alongside graph neural networks to learn both the temporal mechanisms of incoming nodes and the evolving graph topology. However, memory modules only store information about nodes seen at train time, and hence such models cannot be directly transferred to entirely new graphs at test time and deployment. In this work, we study a new transfer learning task for temporal link prediction, and develop transfer-effective methods for memory-laden models. Specifically, motivated by work showing the informativeness of structural signals for the TLP task, we augment a structural mapping module to the existing TLP model architectures, which learns a mapping from graph structural (topological) features to memory embeddings. Our work paves the way for a memory-free foundation model for TLP.
Generating Human Understandable Explanations for Node Embeddings
Jun 11, 2024



Node embedding algorithms produce low-dimensional latent representations of nodes in a graph. These embeddings are often used for downstream tasks, such as node classification and link prediction. In this paper, we investigate the following two questions: (Q1) Can we explain each embedding dimension with human-understandable graph features (e.g. degree, clustering coefficient and PageRank). (Q2) How can we modify existing node embedding algorithms to produce embeddings that can be easily explained by human-understandable graph features? We find that the answer to Q1 is yes and introduce a new framework called XM (short for eXplain eMbedding) to answer Q2. A key aspect of XM involves minimizing the nuclear norm of the generated explanations. We show that by minimizing the nuclear norm, we minimize the lower bound on the entropy of the generated explanations. We test XM on a variety of real-world graphs and show that XM not only preserves the performance of existing node embedding methods, but also enhances their explainability.
GRASP: Accelerating Shortest Path Attacks via Graph Attention
Oct 23, 2023Recent advances in machine learning (ML) have shown promise in aiding and accelerating classical combinatorial optimization algorithms. ML-based speed ups that aim to learn in an end to end manner (i.e., directly output the solution) tend to trade off run time with solution quality. Therefore, solutions that are able to accelerate existing solvers while maintaining their performance guarantees, are of great interest. We consider an APX-hard problem, where an adversary aims to attack shortest paths in a graph by removing the minimum number of edges. We propose the GRASP algorithm: Graph Attention Accelerated Shortest Path Attack, an ML aided optimization algorithm that achieves run times up to 10x faster, while maintaining the quality of solution generated. GRASP uses a graph attention network to identify a smaller subgraph containing the combinatorial solution, thus effectively reducing the input problem size. Additionally, we demonstrate how careful representation of the input graph, including node features that correlate well with the optimization task, can highlight important structure in the optimization solution.
Disentangling Node Attributes from Graph Topology for Improved Generalizability in Link Prediction
Jul 17, 2023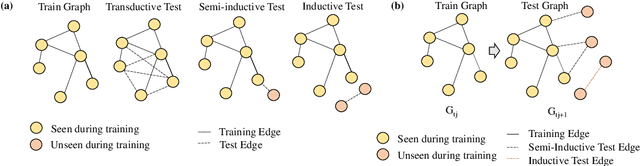

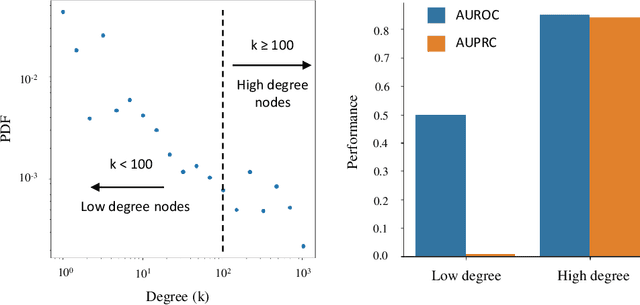

Link prediction is a crucial task in graph machine learning with diverse applications. We explore the interplay between node attributes and graph topology and demonstrate that incorporating pre-trained node attributes improves the generalization power of link prediction models. Our proposed method, UPNA (Unsupervised Pre-training of Node Attributes), solves the inductive link prediction problem by learning a function that takes a pair of node attributes and predicts the probability of an edge, as opposed to Graph Neural Networks (GNN), which can be prone to topological shortcuts in graphs with power-law degree distribution. In this manner, UPNA learns a significant part of the latent graph generation mechanism since the learned function can be used to add incoming nodes to a growing graph. By leveraging pre-trained node attributes, we overcome observational bias and make meaningful predictions about unobserved nodes, surpassing state-of-the-art performance (3X to 34X improvement on benchmark datasets). UPNA can be applied to various pairwise learning tasks and integrated with existing link prediction models to enhance their generalizability and bolster graph generative models.
Quality Assurance in MLOps Setting: An Industrial Perspective
Nov 24, 2022Today, machine learning (ML) is widely used in industry to provide the core functionality of production systems. However, it is practically always used in production systems as part of a larger end-to-end software system that is made up of several other components in addition to the ML model. Due to production demand and time constraints, automated software engineering practices are highly applicable. The increased use of automated ML software engineering practices in industries such as manufacturing and utilities requires an automated Quality Assurance (QA) approach as an integral part of ML software. Here, QA helps reduce risk by offering an objective perspective on the software task. Although conventional software engineering has automated tools for QA data analysis for data-driven ML, the use of QA practices for ML in operation (MLOps) is lacking. This paper examines the QA challenges that arise in industrial MLOps and conceptualizes modular strategies to deal with data integrity and Data Quality (DQ). The paper is accompanied by real industrial use-cases from industrial partners. The paper also presents several challenges that may serve as a basis for future studies.
AI-Bind: Improving Binding Predictions for Novel Protein Targets and Ligands
Dec 28, 2021
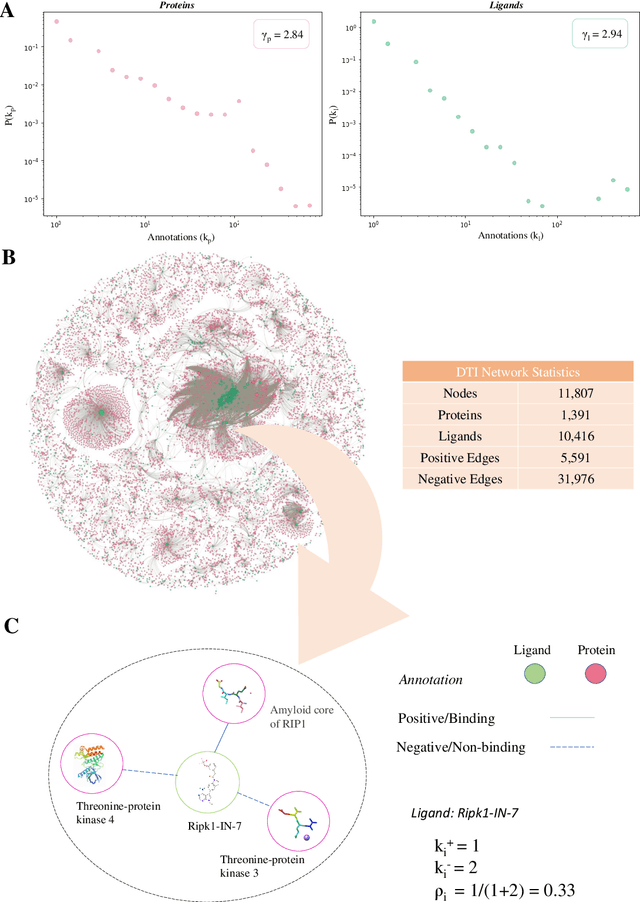

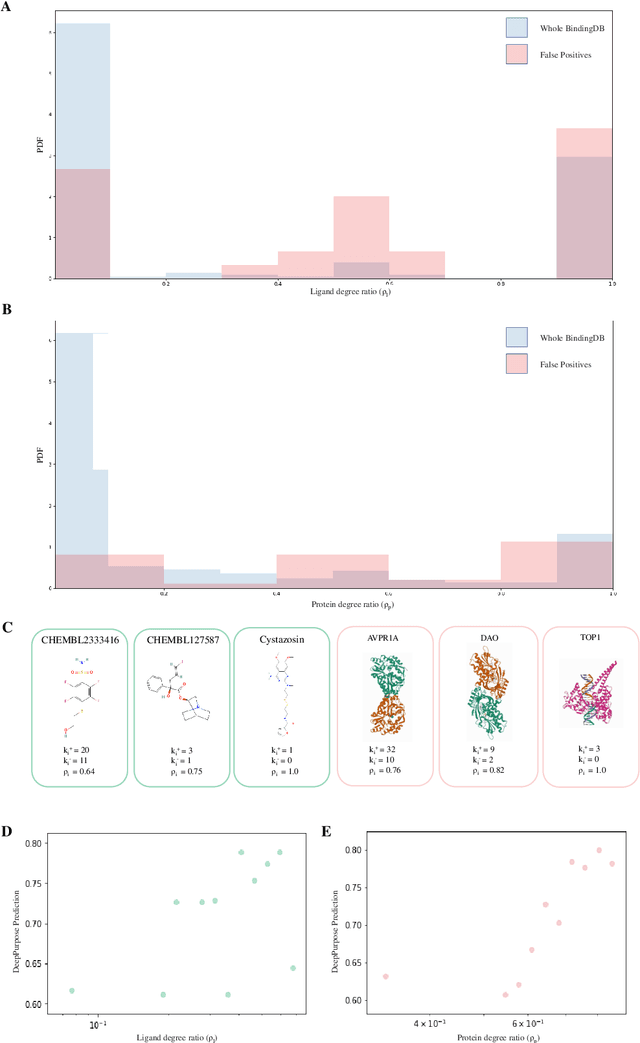
Identifying novel drug-target interactions (DTI) is a critical and rate limiting step in drug discovery. While deep learning models have been proposed to accelerate the identification process, we show that state-of-the-art models fail to generalize to novel (i.e., never-before-seen) structures. We first unveil the mechanisms responsible for this shortcoming, demonstrating how models rely on shortcuts that leverage the topology of the protein-ligand bipartite network, rather than learning the node features. Then, we introduce AI-Bind, a pipeline that combines network-based sampling strategies with unsupervised pre-training, allowing us to limit the annotation imbalance and improve binding predictions for novel proteins and ligands. We illustrate the value of AI-Bind by predicting drugs and natural compounds with binding affinity to SARS-CoV-2 viral proteins and the associated human proteins. We also validate these predictions via auto-docking simulations and comparison with recent experimental evidence. Overall, AI-Bind offers a powerful high-throughput approach to identify drug-target combinations, with the potential of becoming a powerful tool in drug discovery.
Automated Human Activity Recognition by Colliding Bodies Optimization-based Optimal Feature Selection with Recurrent Neural Network
Oct 07, 2020
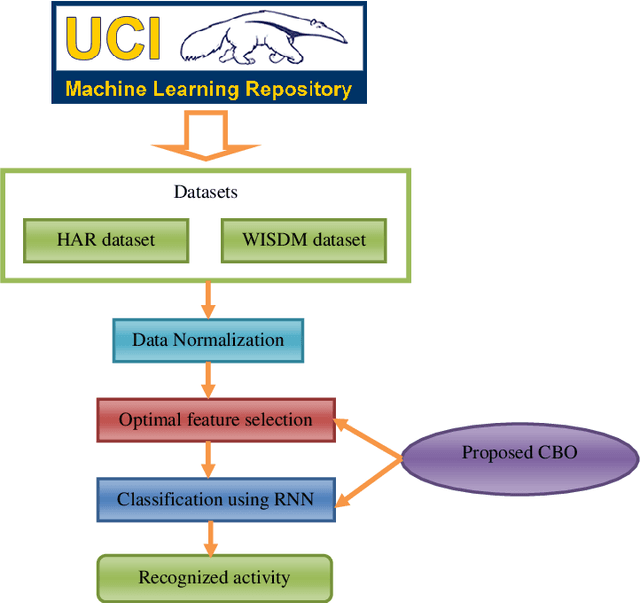

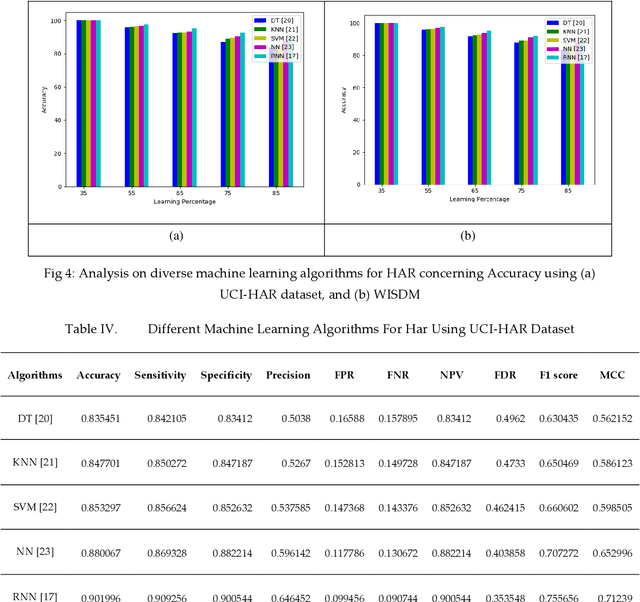
In smart healthcare, Human Activity Recognition (HAR) is considered to be an efficient model in pervasive computation from sensor readings. The Ambient Assisted Living (AAL) in the home or community helps the people in providing independent care and enhanced living quality. However, many AAL models were restricted using many factors that include computational cost and system complexity. Moreover, the HAR concept has more relevance because of its applications. Hence, this paper tempts to implement the HAR system using deep learning with the data collected from smart sensors that are publicly available in the UC Irvine Machine Learning Repository (UCI). The proposed model involves three processes: (1) Data collection, (b) Optimal feature selection, (c) Recognition. The data gathered from the benchmark repository is initially subjected to optimal feature selection that helps to select the most significant features. The proposed optimal feature selection is based on a new meta-heuristic algorithm called Colliding Bodies Optimization (CBO). An objective function derived by the recognition accuracy is used for accomplishing the optimal feature selection. Here, the deep learning model called Recurrent Neural Network (RNN) is used for activity recognition. The proposed model on the concerned benchmark dataset outperforms existing learning methods, providing high performance compared to the conventional models.