 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision annealing Monte Carlo methods for statistical data assimilation and machine learning
Jul 06, 2019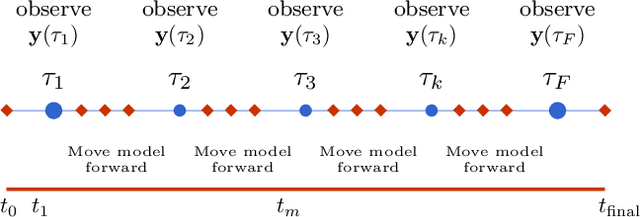
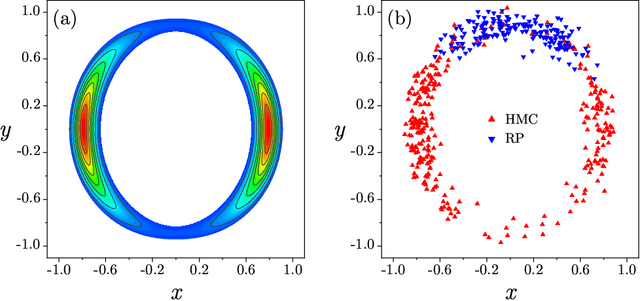

In statistical data assimilation (SDA) and supervised machine learning (ML), we wish to transfer information from observations to a model of the processes underlying those observations. For SDA, the model consists of a set of differential equations that describe the dynamics of a physical system. For ML, the model is usually constructed using other strategies. In this paper, we develop a systematic formulation based on Monte Carlo sampling to achieve such information transfer. Following the derivation of an appropriate target distribution, we present the formulation based on the standard Metropolis-Hasting (MH) procedure and the Hamiltonian Monte Carlo (HMC) method for performing the high dimensional integrals that appear. To the extensive literature on MH and HMC, we add (1) an annealing method using a hyperparameter that governs the precision of the model to identify and explore the highest probability regions of phase space dominating those integrals, and (2) a strategy for initializing the state space search. The efficacy of the proposed formulation is demonstrated using a nonlinear dynamical model with chaotic solutions widely used in geophysics.
Machine Learning of Time Series Using Time-delay Embedding and Precision Annealing
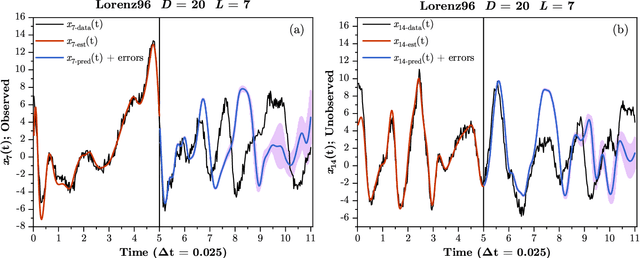
Feb 12, 2019Tasking machine learning to predict segments of a time series requires estimating the parameters of a ML model with input/output pairs from the time series. Using the equivalence between statistical data assimilation and supervised machine learning, we revisit this task. The training method for the machine utilizes a precision annealing approach to identifying the global minimum of the action (-log[P]). In this way we are able to identify the number of training pairs required to produce good generalizations (predictions) for the time series. We proceed from a scalar time series $s(t_n); t_n = t_0 + n \Delta t$ and using methods of nonlinear time series analysis show how to produce a $D_E > 1$ dimensional time delay embedding space in which the time series has no false neighbors as does the observed $s(t_n)$ time series. In that $D_E$-dimensional space we explore the use of feed forward multi-layer perceptrons as network models operating on $D_E$-dimensional input and producing $D_E$-dimensional outputs.