 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Prompting Matters: Rethinking Referring Video Object Segmentation
Oct 08, 2025Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence in the video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we rethink the RVOS problem and aim to investigate the key to this task. Based on existing foundation segmentation models, we decompose the RVOS task into referring, video, and segmentation factors, and propose a Temporal Prompt Generation and Selection (Tenet) framework to address the referring and video factors while leaving the segmentation problem to foundation models. To efficiently adapt image-based foundation segmentation models to referring video object segmentation, we leverage off-the-shelf object detectors and trackers to produce temporal prompts associated with the referring sentence. While high-quality temporal prompts could be produced, they can not be easily identified from confidence scores. To tackle this issue, we propose Prompt Preference Learning to evaluate the quality of the produced temporal prompts. By taking such prompts to instruct image-based foundation segmentation models, we would be able to produce high-quality masks for the referred object, enabling efficient model adaptation to referring video object segmentation. Experiments on RVOS benchmarks demonstrate the effectiveness of the Tenet framework.
GroPrompt: Efficient Grounded Prompting and Adaptation for Referring Video Object Segmentation
Jun 18, 2024

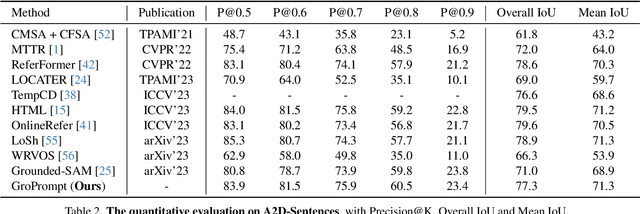

Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence throughout the entire video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we aim to efficiently adapt foundation segmentation models for addressing RVOS from weak supervision with the proposed Grounded Prompting (GroPrompt) framework. More specifically, we propose Text-Aware Prompt Contrastive Learning (TAP-CL) to enhance the association between the position prompts and the referring sentences with only box supervisions, including Text-Contrastive Prompt Learning (TextCon) and Modality-Contrastive Prompt Learning (ModalCon) at frame level and video level, respectively. With the proposed TAP-CL, our GroPrompt framework can generate temporal-consistent yet text-aware position prompts describing locations and movements for the referred object from the video. The experimental results in the standard RVOS benchmarks (Ref-YouTube-VOS, Ref-DAVIS17, A2D-Sentences, and JHMDB-Sentences) demonstrate the competitive performance of our proposed GroPrompt framework given only bounding box weak supervisions.
GSNeRF: Generalizable Semantic Neural Radiance Fields with Enhanced 3D Scene Understanding
Mar 06, 2024Utilizing multi-view inputs to synthesize novel-view images, Neural Radiance Fields (NeRF) have emerged as a popular research topic in 3D vision. In this work, we introduce a Generalizable Semantic Neural Radiance Field (GSNeRF), which uniquely takes image semantics into the synthesis process so that both novel view images and the associated semantic maps can be produced for unseen scenes. Our GSNeRF is composed of two stages: Semantic Geo-Reasoning and Depth-Guided Visual rendering. The former is able to observe multi-view image inputs to extract semantic and geometry features from a scene. Guided by the resulting image geometry information, the latter performs both image and semantic rendering with improved performances. Our experiments not only confirm that GSNeRF performs favorably against prior works on both novel-view image and semantic segmentation synthesis but the effectiveness of our sampling strategy for visual rendering is further verified.
Language-Guided Transformer for Federated Multi-Label Classification
Dec 12, 2023Federated Learning (FL) is an emerging paradigm that enables multiple users to collaboratively train a robust model in a privacy-preserving manner without sharing their private data. Most existing approaches of FL only consider traditional single-label image classification, ignoring the impact when transferring the task to multi-label image classification. Nevertheless, it is still challenging for FL to deal with user heterogeneity in their local data distribution in the real-world FL scenario, and this issue becomes even more severe in multi-label image classification. Inspired by the recent success of Transformers in centralized settings, we propose a novel FL framework for multi-label classification. Since partial label correlation may be observed by local clients during training, direct aggregation of locally updated models would not produce satisfactory performances. Thus, we propose a novel FL framework of Language-Guided Transformer (FedLGT) to tackle this challenging task, which aims to exploit and transfer knowledge across different clients for learning a robust global model. Through extensive experiments on various multi-label datasets (e.g., FLAIR, MS-COCO, etc.), we show that our FedLGT is able to achieve satisfactory performance and outperforms standard FL techniques under multi-label FL scenarios. Code is available at https://github.com/Jack24658735/FedLGT.