 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic 3D Multi-Object Cooperative Tracking for Autonomous Driving via Differentiable Multi-Sensor Kalman Filter
Sep 26, 2023Current state-of-the-art autonomous driving vehicles mainly rely on each individual sensor system to perform perception tasks. Such a framework's reliability could be limited by occlusion or sensor failure. To address this issue, more recent research proposes using vehicle-to-vehicle (V2V) communication to share perception information with others. However, most relevant works focus only on cooperative detection and leave cooperative tracking an underexplored research field. A few recent datasets, such as V2V4Real, provide 3D multi-object cooperative tracking benchmarks. However, their proposed methods mainly use cooperative detection results as input to a standard single-sensor Kalman Filter-based tracking algorithm. In their approach, the measurement uncertainty of different sensors from different connected autonomous vehicles (CAVs) may not be properly estimated to utilize the theoretical optimality property of Kalman Filter-based tracking algorithms. In this paper, we propose a novel 3D multi-object cooperative tracking algorithm for autonomous driving via a differentiable multi-sensor Kalman Filter. Our algorithm learns to estimate measurement uncertainty for each detection that can better utilize the theoretical property of Kalman Filter-based tracking methods. The experiment results show that our algorithm improves the tracking accuracy by 17% with only 0.037x communication costs compared with the state-of-the-art method in V2V4Real.
Collision Avoidance Detour for Multi-Agent Trajectory Forecasting
Jun 20, 2023We present our approach, Collision Avoidance Detour (CAD), which won the 3rd place award in the 2023 Waymo Open Dataset Challenge - Sim Agents, held at the 2023 CVPR Workshop on Autonomous Driving. To satisfy the motion prediction factorization requirement, we partition all the valid objects into three mutually exclusive sets: Autonomous Driving Vehicle (ADV), World-tracks-to-predict, and World-others. We use different motion models to forecast their future trajectories independently. Furthermore, we also apply collision avoidance detour resampling, additive Gaussian noise, and velocity-based heading estimation to improve the realism of our simulation result.
Selective Communication for Cooperative Perception in End-to-End Autonomous Driving
May 26, 2023The reliability of current autonomous driving systems is often jeopardized in situations when the vehicle's field-of-view is limited by nearby occluding objects. To mitigate this problem, vehicle-to-vehicle communication to share sensor information among multiple autonomous driving vehicles has been proposed. However, to enable timely processing and use of shared sensor data, it is necessary to constrain communication bandwidth, and prior work has done so by restricting the number of other cooperative vehicles and randomly selecting the subset of vehicles to exchange information with from all those that are within communication range. Although simple and cost effective from a communication perspective, this selection approach suffers from its susceptibility to missing those vehicles that possess the perception information most critical to navigation planning. Inspired by recent multi-agent path finding research, we propose a novel selective communication algorithm for cooperative perception to address this shortcoming. Implemented with a lightweight perception network and a previously developed control network, our algorithm is shown to produce higher success rates than a random selection approach on previously studied safety-critical driving scenario simulations, with minimal additional communication overhead.
Probabilistic 3D Multi-Modal, Multi-Object Tracking for Autonomous Driving
Dec 26, 2020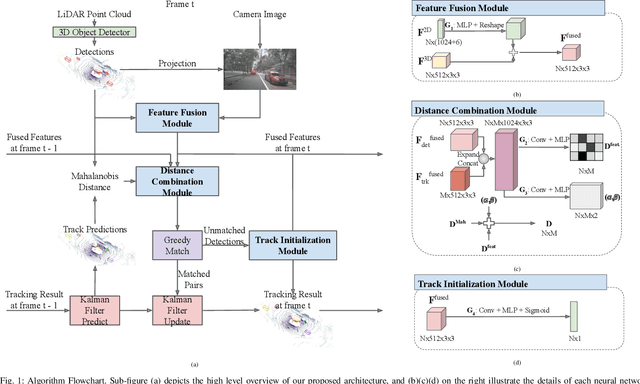



Multi-object tracking is an important ability for an autonomous vehicle to safely navigate a traffic scene. Current state-of-the-art follows the tracking-by-detection paradigm where existing tracks are associated with detected objects through some distance metric. The key challenges to increase tracking accuracy lie in data association and track life cycle management. We propose a probabilistic, multi-modal, multi-object tracking system consisting of different trainable modules to provide robust and data-driven tracking results. First, we learn how to fuse features from 2D images and 3D LiDAR point clouds to capture the appearance and geometric information of an object. Second, we propose to learn a metric that combines the Mahalanobis and feature distances when comparing a track and a new detection in data association. And third, we propose to learn when to initialize a track from an unmatched object detection. Through extensive quantitative and qualitative results, we show that our method outperforms current state-of-the-art on the NuScenes Tracking dataset.
Probabilistic 3D Multi-Object Tracking for Autonomous Driving
Jan 16, 2020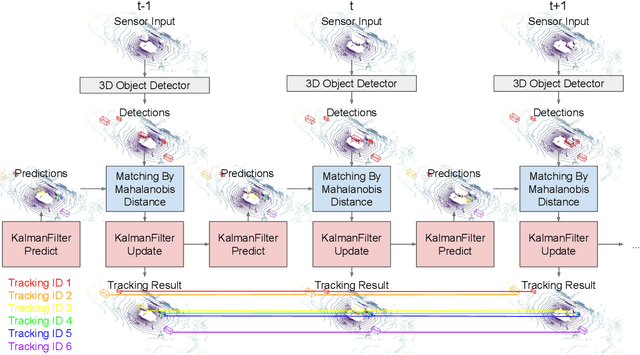
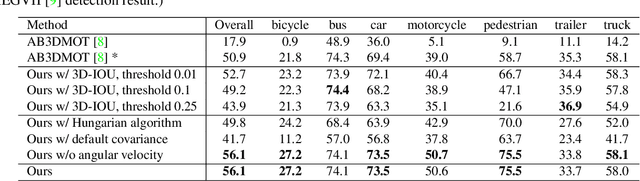

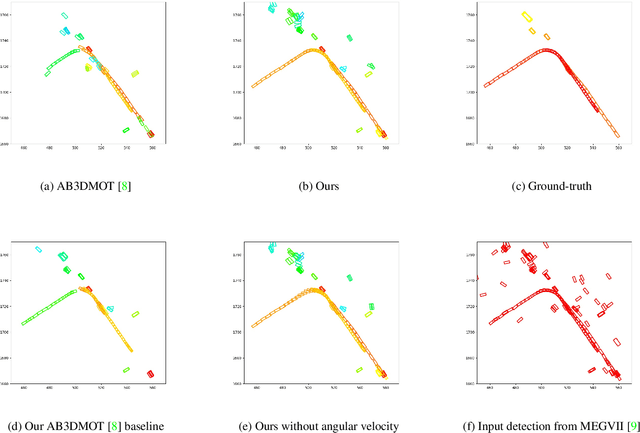
3D multi-object tracking is a key module in autonomous driving applications that provides a reliable dynamic representation of the world to the planning module. In this paper, we present our on-line tracking method, which made the first place in the NuScenes Tracking Challenge, held at the AI Driving Olympics Workshop at NeurIPS 2019. Our method estimates the object states by adopting a Kalman Filter. We initialize the state covariance as well as the process and observation noise covariance with statistics from the training set. We also use the stochastic information from the Kalman Filter in the data association step by measuring the Mahalanobis distance between the predicted object states and current object detections. Our experimental results on the NuScenes validation and test set show that our method outperforms the AB3DMOT baseline method by a large margin in the Average Multi-Object Tracking Accuracy (AMOTA) metric.
Imitation Learning for Human Pose Prediction
Sep 08, 2019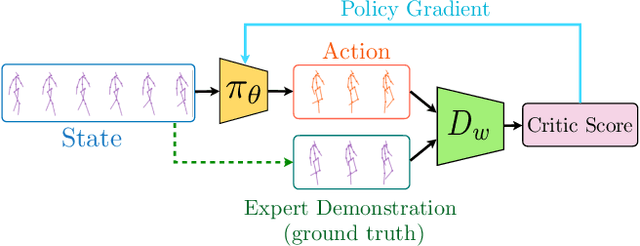
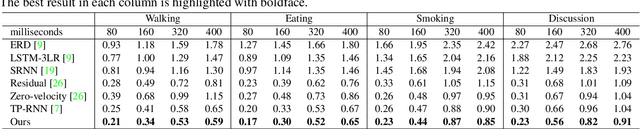
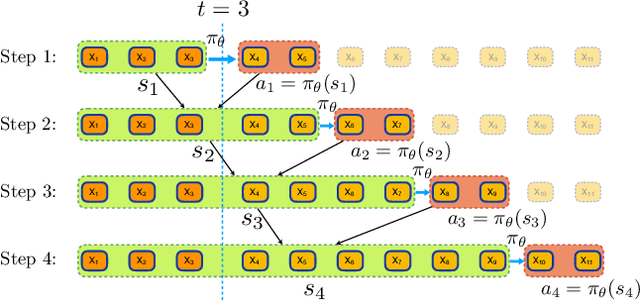
Modeling and prediction of human motion dynamics has long been a challenging problem in computer vision, and most existing methods rely on the end-to-end supervised training of various architectures of recurrent neural networks. Inspired by the recent success of deep reinforcement learning methods, in this paper we propose a new reinforcement learning formulation for the problem of human pose prediction, and develop an imitation learning algorithm for predicting future poses under this formulation through a combination of behavioral cloning and generative adversarial imitation learning. Our experiments show that our proposed method outperforms all existing state-of-the-art baseline models by large margins on the task of human pose prediction in both short-term predictions and long-term predictions, while also enjoying huge advantage in training speed.
Segmenting the Future
Apr 24, 2019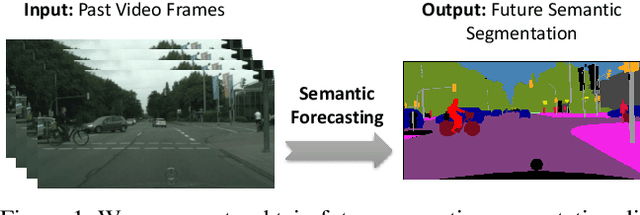

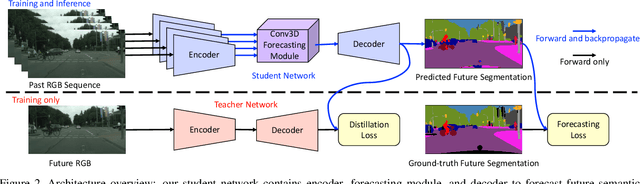

Predicting the future is an important aspect for decision-making in robotics or autonomous driving systems, which heavily rely upon visual scene understanding. While prior work attempts to predict future video pixels, anticipate activities or forecast future scene semantic segments from segmentation of the preceding frames, methods that predict future semantic segmentation solely from the previous frame RGB data in a single end-to-end trainable model do not exist. In this paper, we propose a temporal encoder-decoder network architecture that encodes RGB frames from the past and decodes the future semantic segmentation. The network is coupled with a new knowledge distillation training framework specifically for the forecasting task. Our method, only seeing preceding video frames, implicitly models the scene segments while simultaneously accounting for the object dynamics to infer the future scene semantic segments. Our results on Cityscapes outperform the baseline and current state-of-the-art methods. Code is available at https://github.com/eddyhkchiu/segmenting_the_future/.
Action-Agnostic Human Pose Forecasting
Oct 23, 2018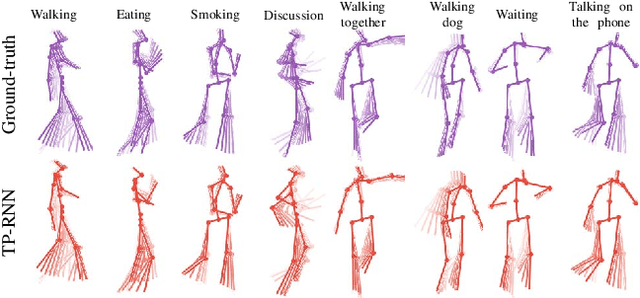
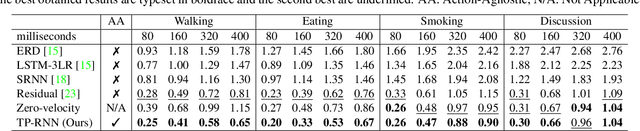
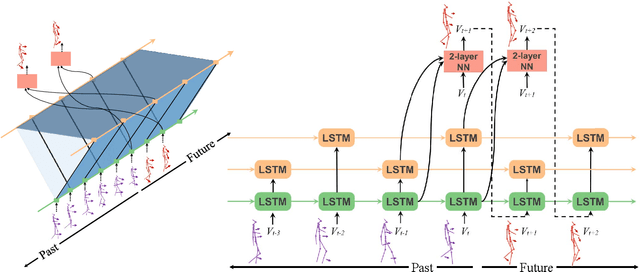
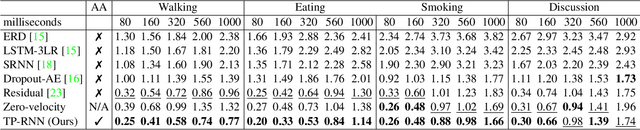
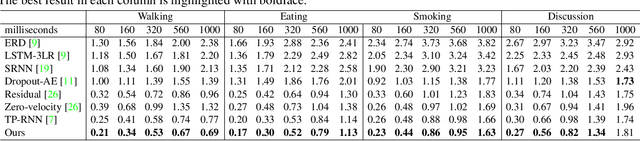
Predicting and forecasting human dynamics is a very interesting but challenging task with several prospective applications in robotics, health-care, etc. Recently, several methods have been developed for human pose forecasting; however, they often introduce a number of limitations in their settings. For instance, previous work either focused only on short-term or long-term predictions, while sacrificing one or the other. Furthermore, they included the activity labels as part of the training process, and require them at testing time. These limitations confine the usage of pose forecasting models for real-world applications, as often there are no activity-related annotations for testing scenarios. In this paper, we propose a new action-agnostic method for short- and long-term human pose forecasting. To this end, we propose a new recurrent neural network for modeling the hierarchical and multi-scale characteristics of the human dynamics, denoted by triangular-prism RNN (TP-RNN). Our model captures the latent hierarchical structure embedded in temporal human pose sequences by encoding the temporal dependencies with different time-scales. For evaluation, we run an extensive set of experiments on Human 3.6M and Penn Action datasets and show that our method outperforms baseline and state-of-the-art methods quantitatively and qualitatively. Codes are available at https://github.com/eddyhkchiu/pose_forecast_wacv/