 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmenting the Future
Paper and Code
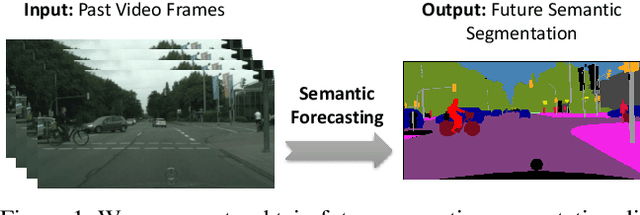

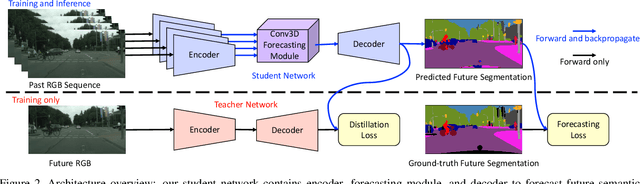

Predicting the future is an important aspect for decision-making in robotics or autonomous driving systems, which heavily rely upon visual scene understanding. While prior work attempts to predict future video pixels, anticipate activities or forecast future scene semantic segments from segmentation of the preceding frames, methods that predict future semantic segmentation solely from the previous frame RGB data in a single end-to-end trainable model do not exist. In this paper, we propose a temporal encoder-decoder network architecture that encodes RGB frames from the past and decodes the future semantic segmentation. The network is coupled with a new knowledge distillation training framework specifically for the forecasting task. Our method, only seeing preceding video frames, implicitly models the scene segments while simultaneously accounting for the object dynamics to infer the future scene semantic segments. Our results on Cityscapes outperform the baseline and current state-of-the-art methods. Code is available at https://github.com/eddyhkchiu/segmenting_the_future/.