 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Decision-Making Into Differentiable Optimization Guided Learning for End-to-End Planning of Autonomous Vehicles
Dec 02, 2024We address the decision-making capability within an end-to-end planning framework that focuses on motion prediction, decision-making, and trajectory planning. Specifically, we formulate decision-making and trajectory planning as a differentiable nonlinear optimization problem, which ensures compatibility with learning-based modules to establish an end-to-end trainable architecture. This optimization introduces explicit objectives related to safety, traveling efficiency, and riding comfort, guiding the learning process in our proposed pipeline. Intrinsic constraints resulting from the decision-making task are integrated into the optimization formulation and preserved throughout the learning process. By integrating the differentiable optimizer with a neural network predictor, the proposed framework is end-to-end trainable, aligning various driving tasks with ultimate performance goals defined by the optimization objectives. The proposed framework is trained and validated using the Waymo Open Motion dataset. The open-loop testing reveals that while the planning outcomes using our method do not always resemble the expert trajectory, they consistently outperform baseline approaches with improved safety, traveling efficiency, and riding comfort. The closed-loop testing further demonstrates the effectiveness of optimizing decisions and improving driving performance. Ablation studies demonstrate that the initialization provided by the learning-based prediction module is essential for the convergence of the optimizer as well as the overall driving performance.
A Universal Multi-Vehicle Cooperative Decision-Making Approach in Structured Roads by Mixed-Integer Potential Game
Sep 24, 2024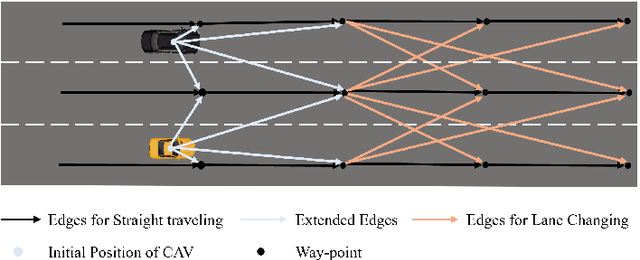
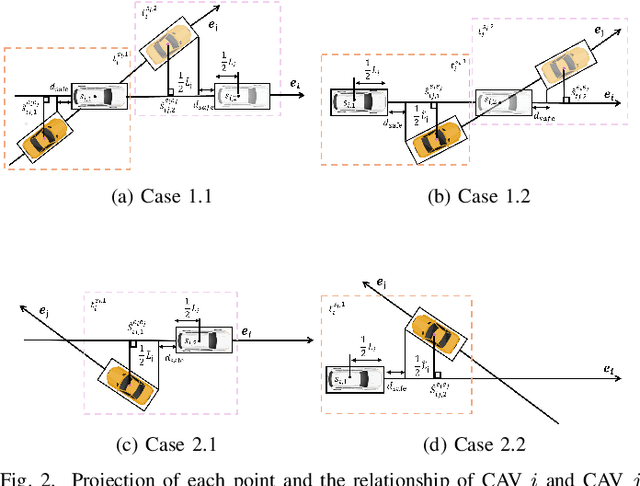
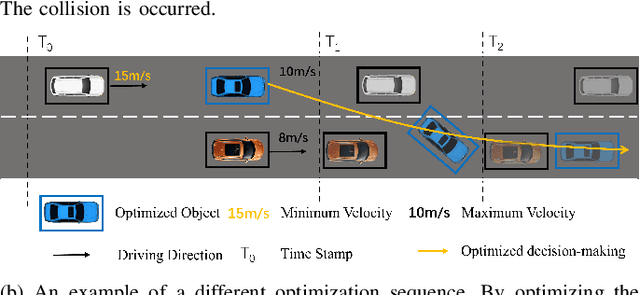
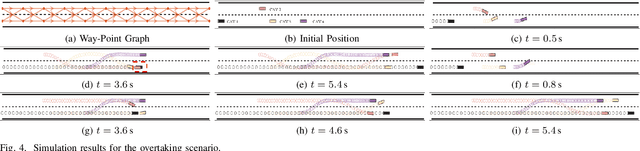
Due to the intricate of real-world road topologies and the inherent complexity of autonomous vehicles, cooperative decision-making for multiple connected autonomous vehicles (CAVs) remains a significant challenge. Currently, most methods are tailored to specific scenarios, and the efficiency of existing optimization and learning methods applicable to diverse scenarios is hindered by the complexity of modeling and data dependency, which limit their real-world applicability. To address these issues, this paper proposes a universal multi-vehicle cooperative decision-making method in structured roads with game theory. We transform the decision-making problem into a graph path searching problem within a way-point graph framework. The problem is formulated as a mixed-integer linear programming problem (MILP) first and transformed into a mixed-integer potential game (MIPG), which reduces the scope of problem and ensures that no player needs to sacrifice for the overall cost. Two Gauss-Seidel algorithms for cooperative decision-making are presented to solve the MIPG problem and obtain the Nash equilibrium solutions. Specifically, the sequential Gauss-Seidel algorithm for cooperative decision-making considers the varying degrees of CAV interactions and flexibility in adjustment strategies to determine optimization priorities, which reduces the frequency of ineffective optimizations. Experimental evaluations across various urban traffic scenarios with different topological structures demonstrate the effectiveness and efficiency of the proposed method compared with MILP and comparisons of different optimization sequences validate the efficiency of the sequential Gauss-Seidel algorithm for cooperative decision-making.
Integrated Intention Prediction and Decision-Making with Spectrum Attention Net and Proximal Policy Optimization
Aug 06, 2024



For autonomous driving in highly dynamic environments, it is anticipated to predict the future behaviors of surrounding vehicles (SVs) and make safe and effective decisions. However, modeling the inherent coupling effect between the prediction and decision-making modules has been a long-standing challenge, especially when there is a need to maintain appropriate computational efficiency. To tackle these problems, we propose a novel integrated intention prediction and decision-making approach, which explicitly models the coupling relationship and achieves efficient computation. Specifically, a spectrum attention net is designed to predict the intentions of SVs by capturing the trends of each frequency component over time and their interrelations. Fast computation of the intention prediction module is attained as the predicted intentions are not decoded to trajectories in the executing process. Furthermore, the proximal policy optimization (PPO) algorithm is employed to address the non-stationary problem in the framework through a modest policy update enabled by a clipping mechanism within its objective function. On the basis of these developments, the intention prediction and decision-making modules are integrated through joint learning. Experiments are conducted in representative traffic scenarios, and the results reveal that the proposed integrated framework demonstrates superior performance over several deep reinforcement learning (DRL) baselines in terms of success rate, efficiency, and safety in driving tasks.
CRPlace: Camera-Radar Fusion with BEV Representation for Place Recognition
Mar 22, 2024The integration of complementary characteristics from camera and radar data has emerged as an effective approach in 3D object detection. However, such fusion-based methods remain unexplored for place recognition, an equally important task for autonomous systems. Given that place recognition relies on the similarity between a query scene and the corresponding candidate scene, the stationary background of a scene is expected to play a crucial role in the task. As such, current well-designed camera-radar fusion methods for 3D object detection can hardly take effect in place recognition because they mainly focus on dynamic foreground objects. In this paper, a background-attentive camera-radar fusion-based method, named CRPlace, is proposed to generate background-attentive global descriptors from multi-view images and radar point clouds for accurate place recognition. To extract stationary background features effectively, we design an adaptive module that generates the background-attentive mask by utilizing the camera BEV feature and radar dynamic points. With the guidance of a background mask, we devise a bidirectional cross-attention-based spatial fusion strategy to facilitate comprehensive spatial interaction between the background information of the camera BEV feature and the radar BEV feature. As the first camera-radar fusion-based place recognition network, CRPlace has been evaluated thoroughly on the nuScenes dataset. The results show that our algorithm outperforms a variety of baseline methods across a comprehensive set of metrics (recall@1 reaches 91.2%).
mmPlace: Robust Place Recognition with Intermediate Frequency Signal of Low-cost Single-chip Millimeter Wave Radar
Mar 07, 2024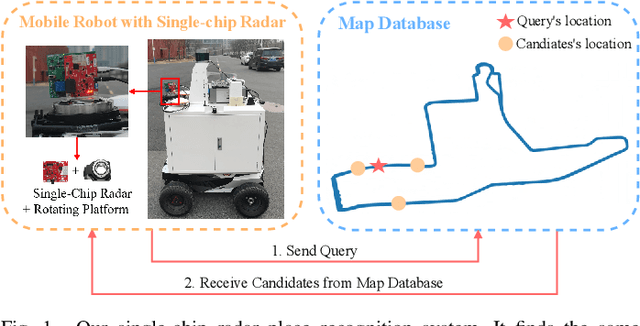

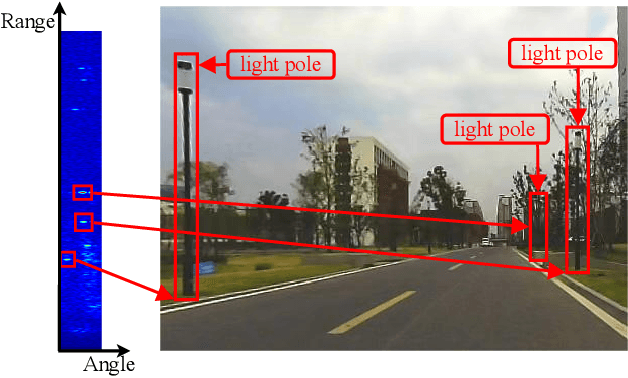
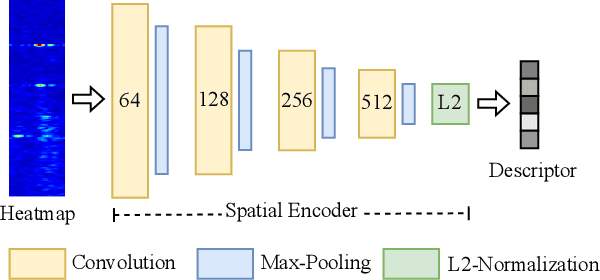
Place recognition is crucial for tasks like loop-closure detection and re-localization. Single-chip millimeter wave radar (single-chip radar in short) emerges as a low-cost sensor option for place recognition, with the advantage of insensitivity to degraded visual environments. However, it encounters two challenges. Firstly, sparse point cloud from single-chip radar leads to poor performance when using current place recognition methods, which assume much denser data. Secondly, its performance significantly declines in scenarios involving rotational and lateral variations, due to limited overlap in its field of view (FOV). We propose mmPlace, a robust place recognition system to address these challenges. Specifically, mmPlace transforms intermediate frequency (IF) signal into range azimuth heatmap and employs a spatial encoder to extract features. Additionally, to improve the performance in scenarios involving rotational and lateral variations, mmPlace employs a rotating platform and concatenates heatmaps in a rotation cycle, effectively expanding the system's FOV. We evaluate mmPlace's performance on the milliSonic dataset, which is collected on the University of Science and Technology of China (USTC) campus, the city roads surrounding the campus, and an underground parking garage. The results demonstrate that mmPlace outperforms point cloud-based methods and achieves 87.37% recall@1 in scenarios involving rotational and lateral variations.
CalibFormer: A Transformer-based Automatic LiDAR-Camera Calibration Network
Nov 26, 2023
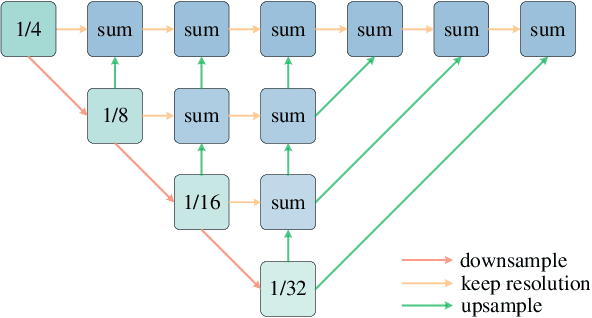

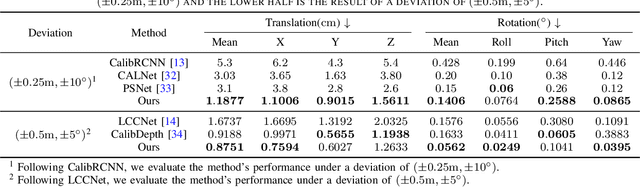
The fusion of LiDARs and cameras has been increasingly adopted in autonomous driving for perception tasks. The performance of such fusion-based algorithms largely depends on the accuracy of sensor calibration, which is challenging due to the difficulty of identifying common features across different data modalities. Previously, many calibration methods involved specific targets and/or manual intervention, which has proven to be cumbersome and costly. Learning-based online calibration methods have been proposed, but their performance is barely satisfactory in most cases. These methods usually suffer from issues such as sparse feature maps, unreliable cross-modality association, inaccurate calibration parameter regression, etc. In this paper, to address these issues, we propose CalibFormer, an end-to-end network for automatic LiDAR-camera calibration. We aggregate multiple layers of camera and LiDAR image features to achieve high-resolution representations. A multi-head correlation module is utilized to identify correlations between features more accurately. Lastly, we employ transformer architectures to estimate accurate calibration parameters from the correlation information. Our method achieved a mean translation error of $0.8751 \mathrm{cm}$ and a mean rotation error of $0.0562 ^{\circ}$ on the KITTI dataset, surpassing existing state-of-the-art methods and demonstrating strong robustness, accuracy, and generalization capabilities.
MAROAM: Map-based Radar SLAM through Two-step Feature Selection
Oct 25, 2022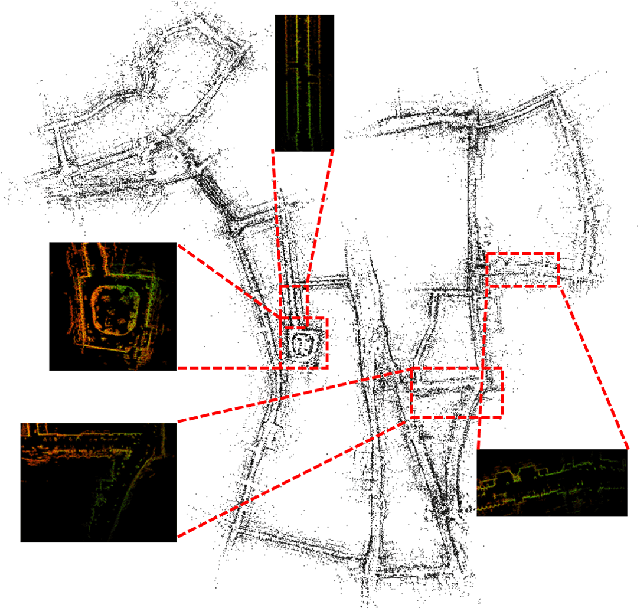
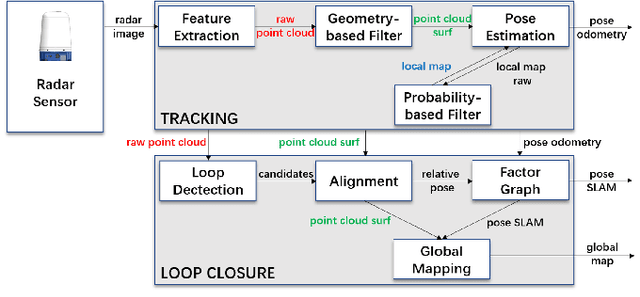


In this letter, we propose MAROAM, a millimeter wave radar-based SLAM framework, which employs a two-step feature selection process to build the global consistent map. Specifically, we first extract feature points from raw data based on their local geometric properties to filter out those points that violate the principle of millimeter-wave radar imaging. Then, we further employ another round of probabilistic feature selection by examining how often and how recent the feature point has been detected in the proceeding frames. With such a two-step feature selection, we establish a global consistent map for accurate and robust pose estimation as well as other downstream tasks. At last, we perform loop closure and graph optimization in the back-end, further reducing the accumulated drift error. We evaluate the performance of MAROAM on the three datasets: the Oxford Radar RobotCar Dataset, the MulRan Dataset and the Boreas Dataset. We consider a variety of experimental settings with different scenery, weather, and road conditions. The experimental results show that the accuracy of MAROAM is 7.95%, 37.0% and 8.9% higher than the currently best-performing algorithms on these three datasets, respectively. The ablation results also show that our map-based odometry performs 28.6% better than the commonly used scan-to-frames method. Finally, as devoted contributors to the open-source community, we will open source the algorithm after the paper is accepted.