 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2024 Challenges Results
Sep 16, 2024

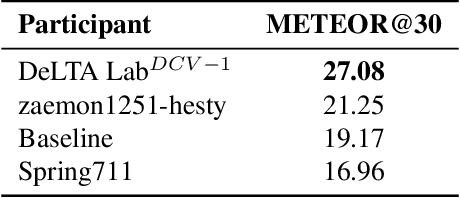
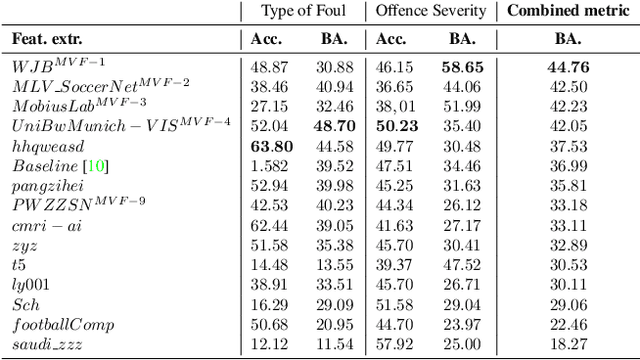
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
CORP: A Multi-Modal Dataset for Campus-Oriented Roadside Perception Tasks
Apr 04, 2024Numerous roadside perception datasets have been introduced to propel advancements in autonomous driving and intelligent transportation systems research and development. However, it has been observed that the majority of their concentrates is on urban arterial roads, inadvertently overlooking residential areas such as parks and campuses that exhibit entirely distinct characteristics. In light of this gap, we propose CORP, which stands as the first public benchmark dataset tailored for multi-modal roadside perception tasks under campus scenarios. Collected in a university campus, CORP consists of over 205k images plus 102k point clouds captured from 18 cameras and 9 LiDAR sensors. These sensors with different configurations are mounted on roadside utility poles to provide diverse viewpoints within the campus region. The annotations of CORP encompass multi-dimensional information beyond 2D and 3D bounding boxes, providing extra support for 3D seamless tracking and instance segmentation with unique IDs and pixel masks for identifying targets, to enhance the understanding of objects and their behaviors distributed across the campus premises. Unlike other roadside datasets about urban traffic, CORP extends the spectrum to highlight the challenges for multi-modal perception in campuses and other residential areas.
CalibFormer: A Transformer-based Automatic LiDAR-Camera Calibration Network
Nov 26, 2023
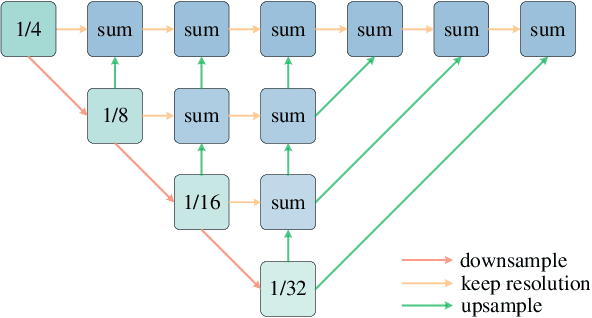

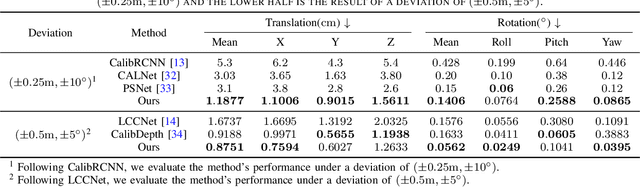
The fusion of LiDARs and cameras has been increasingly adopted in autonomous driving for perception tasks. The performance of such fusion-based algorithms largely depends on the accuracy of sensor calibration, which is challenging due to the difficulty of identifying common features across different data modalities. Previously, many calibration methods involved specific targets and/or manual intervention, which has proven to be cumbersome and costly. Learning-based online calibration methods have been proposed, but their performance is barely satisfactory in most cases. These methods usually suffer from issues such as sparse feature maps, unreliable cross-modality association, inaccurate calibration parameter regression, etc. In this paper, to address these issues, we propose CalibFormer, an end-to-end network for automatic LiDAR-camera calibration. We aggregate multiple layers of camera and LiDAR image features to achieve high-resolution representations. A multi-head correlation module is utilized to identify correlations between features more accurately. Lastly, we employ transformer architectures to estimate accurate calibration parameters from the correlation information. Our method achieved a mean translation error of $0.8751 \mathrm{cm}$ and a mean rotation error of $0.0562 ^{\circ}$ on the KITTI dataset, surpassing existing state-of-the-art methods and demonstrating strong robustness, accuracy, and generalization capabilities.