 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMPlanner: Integrating Visual Language Models with Motion Planning
Jul 27, 2025Integrating large language models (LLMs) into autonomous driving motion planning has recently emerged as a promising direction, offering enhanced interpretability, better controllability, and improved generalization in rare and long-tail scenarios. However, existing methods often rely on abstracted perception or map-based inputs, missing crucial visual context, such as fine-grained road cues, accident aftermath, or unexpected obstacles, which are essential for robust decision-making in complex driving environments. To bridge this gap, we propose VLMPlanner, a hybrid framework that combines a learning-based real-time planner with a vision-language model (VLM) capable of reasoning over raw images. The VLM processes multi-view images to capture rich, detailed visual information and leverages its common-sense reasoning capabilities to guide the real-time planner in generating robust and safe trajectories. Furthermore, we develop the Context-Adaptive Inference Gate (CAI-Gate) mechanism that enables the VLM to mimic human driving behavior by dynamically adjusting its inference frequency based on scene complexity, thereby achieving an optimal balance between planning performance and computational efficiency. We evaluate our approach on the large-scale, challenging nuPlan benchmark, with comprehensive experimental results demonstrating superior planning performance in scenarios with intricate road conditions and dynamic elements. Code will be available.
CAFE-AD: Cross-Scenario Adaptive Feature Enhancement for Trajectory Planning in Autonomous Driving
Apr 09, 2025Imitation learning based planning tasks on the nuPlan dataset have gained great interest due to their potential to generate human-like driving behaviors. However, open-loop training on the nuPlan dataset tends to cause causal confusion during closed-loop testing, and the dataset also presents a long-tail distribution of scenarios. These issues introduce challenges for imitation learning. To tackle these problems, we introduce CAFE-AD, a Cross-Scenario Adaptive Feature Enhancement for Trajectory Planning in Autonomous Driving method, designed to enhance feature representation across various scenario types. We develop an adaptive feature pruning module that ranks feature importance to capture the most relevant information while reducing the interference of noisy information during training. Moreover, we propose a cross-scenario feature interpolation module that enhances scenario information to introduce diversity, enabling the network to alleviate over-fitting in dominant scenarios. We evaluate our method CAFE-AD on the challenging public nuPlan Test14-Hard closed-loop simulation benchmark. The results demonstrate that CAFE-AD outperforms state-of-the-art methods including rule-based and hybrid planners, and exhibits the potential in mitigating the impact of long-tail distribution within the dataset. Additionally, we further validate its effectiveness in real-world environments. The code and models will be made available at https://github.com/AlniyatRui/CAFE-AD.
CORP: A Multi-Modal Dataset for Campus-Oriented Roadside Perception Tasks
Apr 04, 2024



Numerous roadside perception datasets have been introduced to propel advancements in autonomous driving and intelligent transportation systems research and development. However, it has been observed that the majority of their concentrates is on urban arterial roads, inadvertently overlooking residential areas such as parks and campuses that exhibit entirely distinct characteristics. In light of this gap, we propose CORP, which stands as the first public benchmark dataset tailored for multi-modal roadside perception tasks under campus scenarios. Collected in a university campus, CORP consists of over 205k images plus 102k point clouds captured from 18 cameras and 9 LiDAR sensors. These sensors with different configurations are mounted on roadside utility poles to provide diverse viewpoints within the campus region. The annotations of CORP encompass multi-dimensional information beyond 2D and 3D bounding boxes, providing extra support for 3D seamless tracking and instance segmentation with unique IDs and pixel masks for identifying targets, to enhance the understanding of objects and their behaviors distributed across the campus premises. Unlike other roadside datasets about urban traffic, CORP extends the spectrum to highlight the challenges for multi-modal perception in campuses and other residential areas.
RiWNet: A moving object instance segmentation Network being Robust in adverse Weather conditions
Sep 04, 2021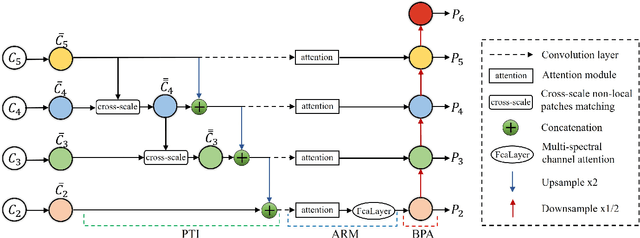

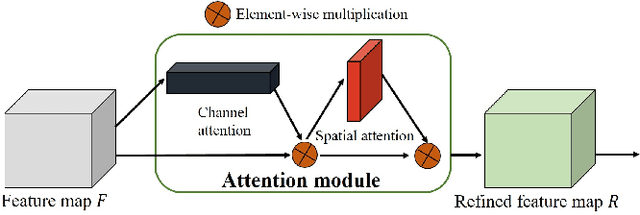
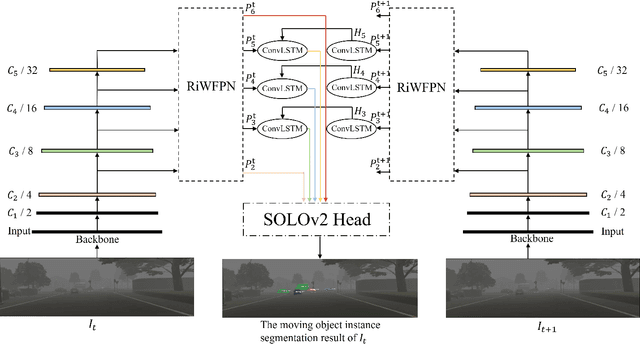
Segmenting each moving object instance in a scene is essential for many applications. But like many other computer vision tasks, this task performs well in optimal weather, but then adverse weather tends to fail. To be robust in weather conditions, the usual way is to train network in data of given weather pattern or to fuse multiple sensors. We focus on a new possibility, that is, to improve its resilience to weather interference through the network's structural design. First, we propose a novel FPN structure called RiWFPN with a progressive top-down interaction and attention refinement module. RiWFPN can directly replace other FPN structures to improve the robustness of the network in non-optimal weather conditions. Then we extend SOLOV2 to capture temporal information in video to learn motion information, and propose a moving object instance segmentation network with RiWFPN called RiWNet. Finally, in order to verify the effect of moving instance segmentation in different weather disturbances, we propose a VKTTI-moving dataset which is a moving instance segmentation dataset based on the VKTTI dataset, taking into account different weather scenes such as rain, fog, sunset, morning as well as overcast. The experiment proves how RiWFPN improves the network's resilience to adverse weather effects compared to other FPN structures. We compare RiWNet to several other state-of-the-art methods in some challenging datasets, and RiWNet shows better performance especially under adverse weather conditions.
Object Detection based on OcSaFPN in Aerial Images with Noise
Dec 18, 2020

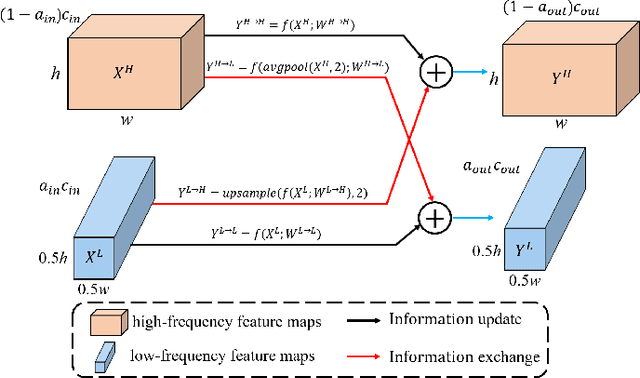
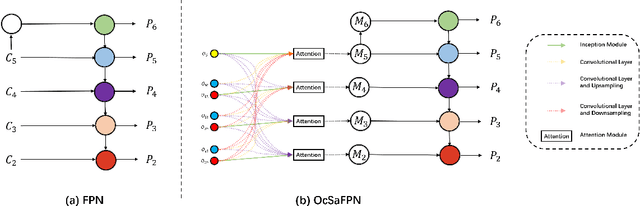
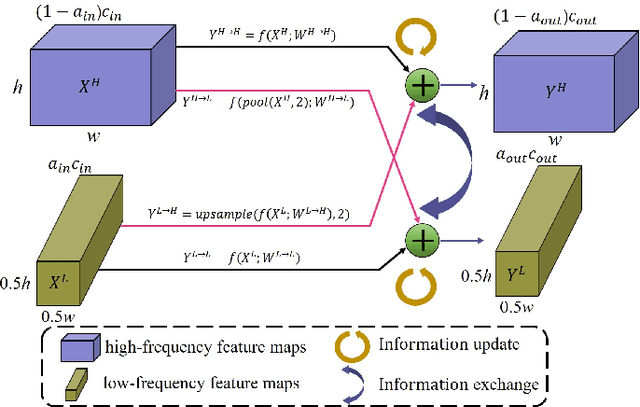
Taking the deep learning-based algorithms into account has become a crucial way to boost object detection performance in aerial images. While various neural network representations have been developed, previous works are still inefficient to investigate the noise-resilient performance, especially on aerial images with noise taken by the cameras with telephoto lenses, and most of the research is concentrated in the field of denoising. Of course, denoising usually requires an additional computational burden to obtain higher quality images, while noise-resilient is more of a description of the robustness of the network itself to different noises, which is an attribute of the algorithm itself. For this reason, the work will be started by analyzing the noise-resilient performance of the neural network, and then propose two hypotheses to build a noise-resilient structure. Based on these hypotheses, we compare the noise-resilient ability of the Oct-ResNet with frequency division processing and the commonly used ResNet. In addition, previous feature pyramid networks used for aerial object detection tasks are not specifically designed for the frequency division feature maps of the Oct-ResNet, and they usually lack attention to bridging the semantic gap between diverse feature maps from different depths. On the basis of this, a novel octave convolution-based semantic attention feature pyramid network (OcSaFPN) is proposed to get higher accuracy in object detection with noise. The proposed algorithm tested on three datasets demonstrates that the proposed OcSaFPN achieves a state-of-the-art detection performance with Gaussian noise or multiplicative noise. In addition, more experiments have proved that the OcSaFPN structure can be easily added to existing algorithms, and the noise-resilient ability can be effectively improved.
U2-ONet: A Two-level Nested Octave U-structure with Multiscale Attention Mechanism for Moving Instances Segmentation
Jul 26, 2020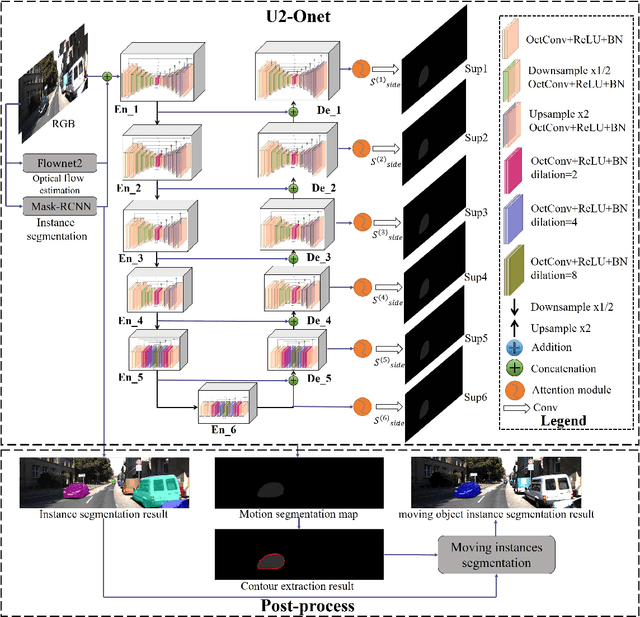
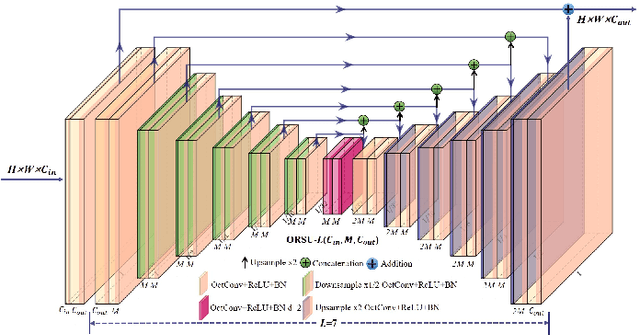
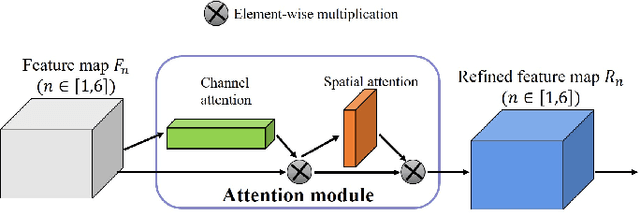
Most scenes in practical applications are dynamic scenes containing moving objects, so segmenting accurately moving objects is crucial for many computer vision applications. In order to efficiently segment out all moving objects in the scene, regardless of whether the object has a predefined semantic label, we propose a two-level nested Octave U-structure network with a multiscale attention mechanism called U2-ONet. Each stage of U2-ONet is filled with our newly designed Octave ReSidual U-block (ORSU) to enhance the ability to obtain more context information at different scales while reducing spatial redundancy of feature maps. In order to efficiently train our multi-scale deep network, we introduce a hierarchical training supervision strategy that calculates the loss at each level while adding a knowledge matching loss to keep the optimization consistency. Experimental results show that our method achieves state-of-the-art performance in several general moving objects segmentation datasets.
DymSLAM:4D Dynamic Scene Reconstruction Based on Geometrical Motion Segmentation
Mar 10, 2020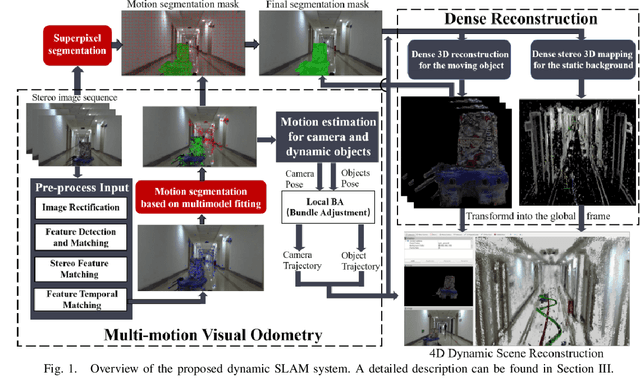

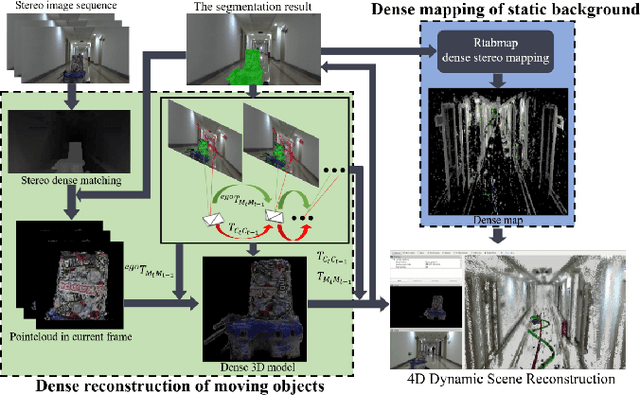

Most SLAM algorithms are based on the assumption that the scene is static. However, in practice, most scenes are dynamic which usually contains moving objects, these methods are not suitable. In this paper, we introduce DymSLAM, a dynamic stereo visual SLAM system being capable of reconstructing a 4D (3D + time) dynamic scene with rigid moving objects. The only input of DymSLAM is stereo video, and its output includes a dense map of the static environment, 3D model of the moving objects and the trajectories of the camera and the moving objects. We at first detect and match the interesting points between successive frames by using traditional SLAM methods. Then the interesting points belonging to different motion models (including ego-motion and motion models of rigid moving objects) are segmented by a multi-model fitting approach. Based on the interesting points belonging to the ego-motion, we are able to estimate the trajectory of the camera and reconstruct the static background. The interesting points belonging to the motion models of rigid moving objects are then used to estimate their relative motion models to the camera and reconstruct the 3D models of the objects. We then transform the relative motion to the trajectories of the moving objects in the global reference frame. Finally, we then fuse the 3D models of the moving objects into the 3D map of the environment by considering their motion trajectories to obtain a 4D (3D+time) sequence. DymSLAM obtains information about the dynamic objects instead of ignoring them and is suitable for unknown rigid objects. Hence, the proposed system allows the robot to be employed for high-level tasks, such as obstacle avoidance for dynamic objects. We conducted experiments in a real-world environment where both the camera and the objects were moving in a wide range.