 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Grasping Strategies Using Event Camera
Paper and Code
Jul 15, 2021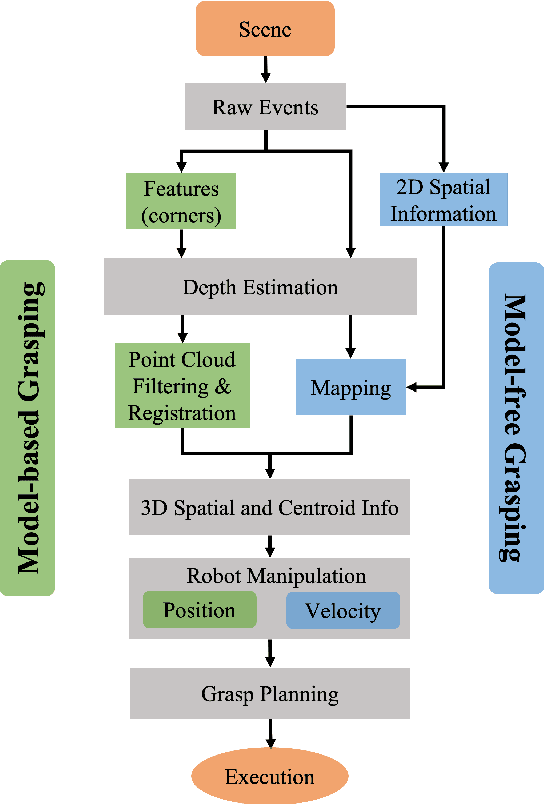

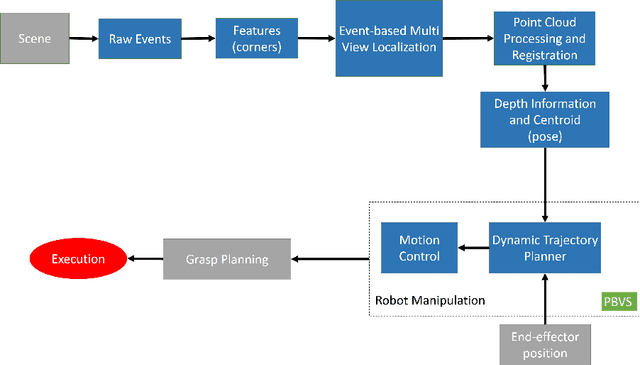

Robotic vision plays a key role for perceiving the environment in grasping applications. However, the conventional framed-based robotic vision, suffering from motion blur and low sampling rate, may not meet the automation needs of evolving industrial requirements. This paper, for the first time, proposes an event-based robotic grasping framework for multiple known and unknown objects in a cluttered scene. Compared with standard frame-based vision, neuromorphic vision has advantages of microsecond-level sampling rate and no motion blur. Building on that, the model-based and model-free approaches are developed for known and unknown objects' grasping respectively. For the model-based approach, event-based multi-view approach is used to localize the objects in the scene, and then point cloud processing allows for the clustering and registering of objects. Differently, the proposed model-free approach utilizes the developed event-based object segmentation, visual servoing and grasp planning to localize, align to, and grasp the targeting object. The proposed approaches are experimentally validated with objects of different sizes, using a UR10 robot with an eye-in-hand neuromorphic camera and a Barrett hand gripper. Moreover, the robustness of the two proposed event-based grasping approaches are validated in a low-light environment. This low-light operating ability shows a great advantage over the grasping using the standard frame-based vision. Furthermore, the developed model-free approach demonstrates the advantage of dealing with unknown object without prior knowledge compared to the proposed model-based approach.