 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection for Industrial Applications, Its Challenges, Solutions, and Future Directions: A Review
Jan 20, 2025



Anomaly detection from images captured using camera sensors is one of the mainstream applications at the industrial level. Particularly, it maintains the quality and optimizes the efficiency in production processes across diverse industrial tasks, including advanced manufacturing and aerospace engineering. Traditional anomaly detection workflow is based on a manual inspection by human operators, which is a tedious task. Advances in intelligent automated inspection systems have revolutionized the Industrial Anomaly Detection (IAD) process. Recent vision-based approaches can automatically extract, process, and interpret features using computer vision and align with the goals of automation in industrial operations. In light of the shift in inspection methodologies, this survey reviews studies published since 2019, with a specific focus on vision-based anomaly detection. The components of an IAD pipeline that are overlooked in existing surveys are presented, including areas related to data acquisition, preprocessing, learning mechanisms, and evaluation. In addition to the collected publications, several scientific and industry-related challenges and their perspective solutions are highlighted. Popular and relevant industrial datasets are also summarized, providing further insight into inspection applications. Finally, future directions of vision-based IAD are discussed, offering researchers insight into the state-of-the-art of industrial inspection.
MSANet: Multi-Similarity and Attention Guidance for Boosting Few-Shot Segmentation
Jun 20, 2022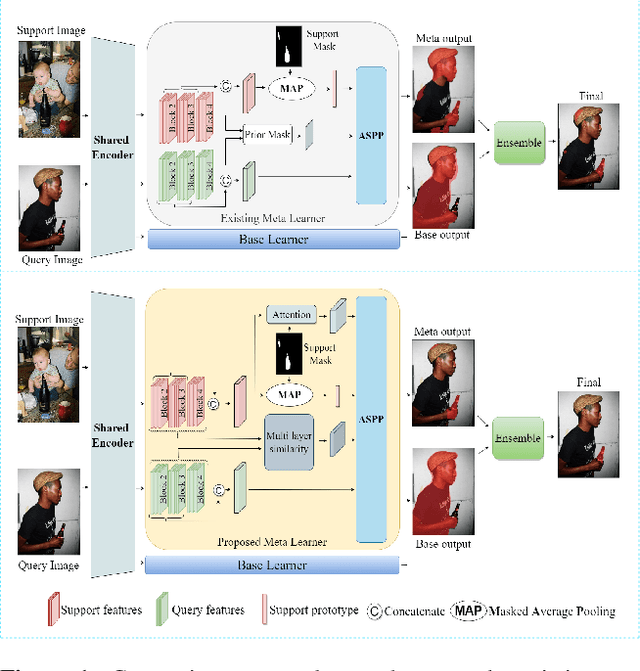
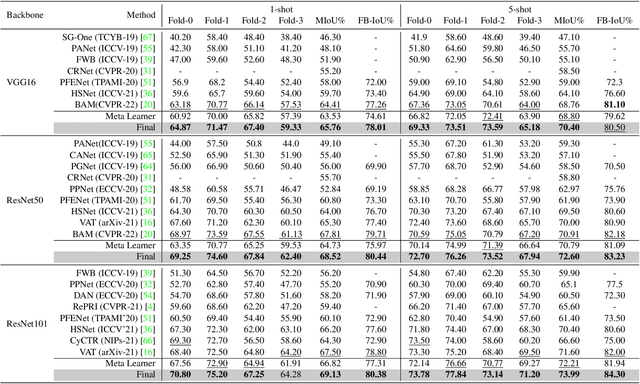

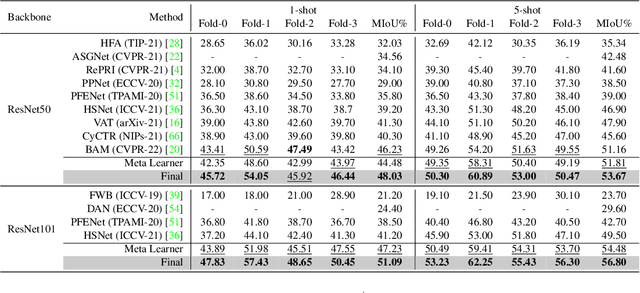
Few-shot segmentation aims to segment unseen-class objects given only a handful of densely labeled samples. Prototype learning, where the support feature yields a singleor several prototypes by averaging global and local object information, has been widely used in FSS. However, utilizing only prototype vectors may be insufficient to represent the features for all training data. To extract abundant features and make more precise predictions, we propose a Multi-Similarity and Attention Network (MSANet) including two novel modules, a multi-similarity module and an attention module. The multi-similarity module exploits multiple feature-maps of support images and query images to estimate accurate semantic relationships. The attention module instructs the network to concentrate on class-relevant information. The network is tested on standard FSS datasets, PASCAL-5i 1-shot, PASCAL-5i 5-shot, COCO-20i 1-shot, and COCO-20i 5-shot. The MSANet with the backbone of ResNet-101 achieves the state-of-the-art performance for all 4-benchmark datasets with mean intersection over union (mIoU) of 69.13%, 73.99%, 51.09%, 56.80%, respectively. Code is available at https://github.com/AIVResearch/MSANet
Saliency-Driven Active Contour Model for Image Segmentation
May 23, 2022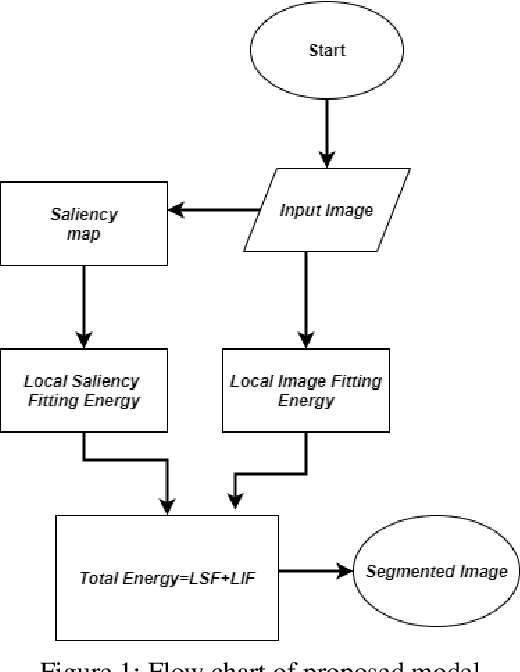
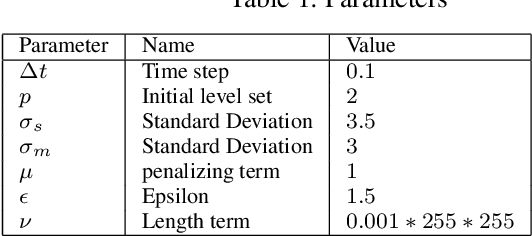

Active contour models have achieved prominent success in the area of image segmentation, allowing complex objects to be segmented from the background for further analysis. Existing models can be divided into region-based active contour models and edge-based active contour models. However, both models use direct image data to achieve segmentation and face many challenging problems in terms of the initial contour position, noise sensitivity, local minima and inefficiency owing to the in-homogeneity of image intensities. The saliency map of an image changes the image representation, making it more visual and meaningful. In this study, we propose a novel model that uses the advantages of a saliency map with local image information (LIF) and overcomes the drawbacks of previous models. The proposed model is driven by a saliency map of an image and the local image information to enhance the progress of the active contour models. In this model, the saliency map of an image is first computed to find the saliency driven local fitting energy. Then, the saliency-driven local fitting energy is combined with the LIF model, resulting in a final novel energy functional. This final energy functional is formulated through a level set formulation, and regulation terms are added to evolve the contour more precisely across the object boundaries. The quality of the proposed method was verified on different synthetic images, real images and publicly available datasets, including medical images. The image segmentation results, and quantitative comparisons confirmed the contour initialization independence, noise insensitivity, and superior segmentation accuracy of the proposed model in comparison to the other segmentation models.
Contextualised concept embedding for efficiently adapting natural language processing models for phenotype identification
Mar 13, 2019
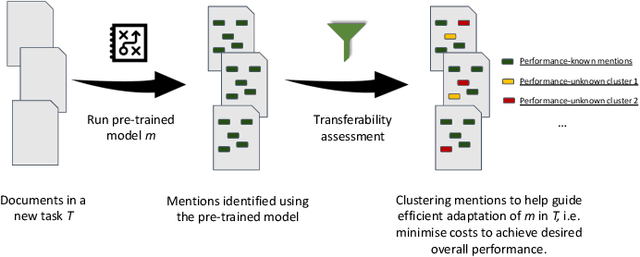
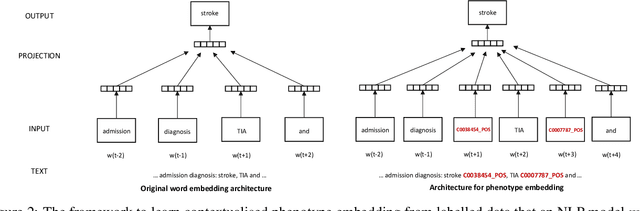
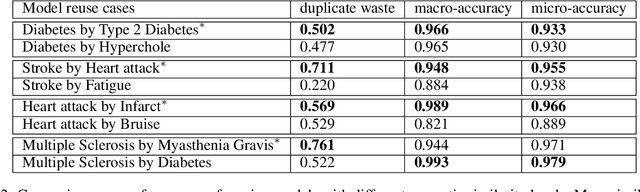
Many efforts have been put to use automated approaches, such as natural language processing (NLP), to mine or extract data from free-text medical records to picture comprehensive patient profiles for delivering better health-care. Reusing NLP models in new settings, however, remains cumbersome - requiring validation and/or retraining on new data iteratively to achieve convergent results. In this paper, we formally define and analyse the NLP model adaptation problem, particularly in phenotype identification tasks, and identify two types of common unnecessary or wasted efforts: duplicate waste and imbalance waste. A distributed representation approach is proposed to represent familiar language patterns for an NLP model by learning phenotype embeddings from its training data. Computations on these language patterns are then introduced to help avoid or reduce unnecessary efforts by combining both geometric and semantic similarities. To evaluate the approach, we cross validate NLP models developed for six physical morbidity studies (23 phenotypes; 17 million documents) on anonymised medical records of South London Maudsley NHS Trust, United Kingdom. Two metrics are introduced to quantify the reductions for both duplicate and imbalance wastes. We conducted various experiments on reusing NLP models in four phenotype identification tasks. Our approach can choose a best model for a given new task, which can identify up to 76% mentions needing no validation & model retraining, meanwhile, having very good performances (93-97% accuracy). It can also provide guidance for validating and retraining the model for novel language patterns in new tasks, which can help save around 80% of the efforts required in blind model-adaptation approaches.