 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling On-device Continual Learning with Binary Neural Networks
Jan 18, 2024


On-device learning remains a formidable challenge, especially when dealing with resource-constrained devices that have limited computational capabilities. This challenge is primarily rooted in two key issues: first, the memory available on embedded devices is typically insufficient to accommodate the memory-intensive back-propagation algorithm, which often relies on floating-point precision. Second, the development of learning algorithms on models with extreme quantization levels, such as Binary Neural Networks (BNNs), is critical due to the drastic reduction in bit representation. In this study, we propose a solution that combines recent advancements in the field of Continual Learning (CL) and Binary Neural Networks to enable on-device training while maintaining competitive performance. Specifically, our approach leverages binary latent replay (LR) activations and a novel quantization scheme that significantly reduces the number of bits required for gradient computation. The experimental validation demonstrates a significant accuracy improvement in combination with a noticeable reduction in memory requirement, confirming the suitability of our approach in expanding the practical applications of deep learning in real-world scenarios.
On-Device Learning with Binary Neural Networks
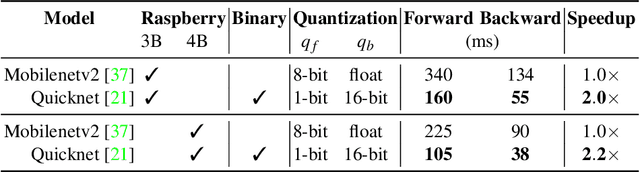
Aug 29, 2023



Existing Continual Learning (CL) solutions only partially address the constraints on power, memory and computation of the deep learning models when deployed on low-power embedded CPUs. In this paper, we propose a CL solution that embraces the recent advancements in CL field and the efficiency of the Binary Neural Networks (BNN), that use 1-bit for weights and activations to efficiently execute deep learning models. We propose a hybrid quantization of CWR* (an effective CL approach) that considers differently forward and backward pass in order to retain more precision during gradient update step and at the same time minimizing the latency overhead. The choice of a binary network as backbone is essential to meet the constraints of low power devices and, to the best of authors' knowledge, this is the first attempt to prove on-device learning with BNN. The experimental validation carried out confirms the validity and the suitability of the proposed method.
Input Layer Binarization with Bit-Plane Encoding
May 04, 2023Binary Neural Networks (BNNs) use 1-bit weights and activations to efficiently execute deep convolutional neural networks on edge devices. Nevertheless, the binarization of the first layer is conventionally excluded, as it leads to a large accuracy loss. The few works addressing the first layer binarization, typically increase the number of input channels to enhance data representation; such data expansion raises the amount of operations needed and it is feasible only on systems with enough computational resources. In this work, we present a new method to binarize the first layer using directly the 8-bit representation of input data; we exploit the standard bit-planes encoding to extract features bit-wise (using depth-wise convolutions); after a re-weighting stage, features are fused again. The resulting model is fully binarized and our first layer binarization approach is model independent. The concept is evaluated on three classification datasets (CIFAR10, SVHN and CIFAR100) for different model architectures (VGG and ResNet) and, the proposed technique outperforms state of the art methods both in accuracy and BMACs reduction.