 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInDistill: Transferring Knowledge From Pruned Intermediate Layers
Paper and Code


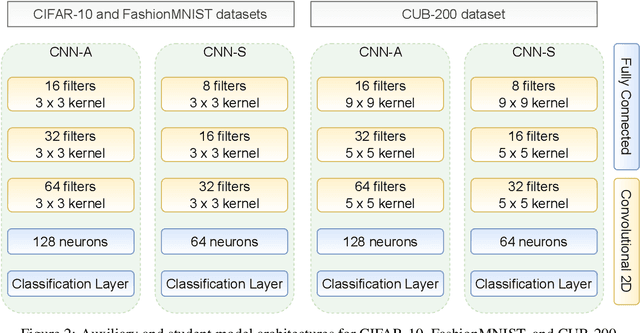

Deploying deep neural networks on hardware with limited resources, such as smartphones and drones, constitutes a great challenge due to their computational complexity. Knowledge distillation approaches aim at transferring knowledge from a large model to a lightweight one, also known as teacher and student respectively, while distilling the knowledge from intermediate layers provides an additional supervision to that task. The capacity gap between the models, the information encoding that collapses its architectural alignment, and the absence of appropriate learning schemes for transferring multiple layers restrict the performance of existing methods. In this paper, we propose a novel method, termed InDistill, that can drastically improve the performance of existing single-layer knowledge distillation methods by leveraging the properties of channel pruning to both reduce the capacity gap between the models and retain the architectural alignment. Furthermore, we propose a curriculum learning based scheme for enhancing the effectiveness of transferring knowledge from multiple intermediate layers. The proposed method surpasses state-of-the-art performance on three benchmark image datasets.