 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large-scale Multimedia Datasets to Refine Content Moderation Models
Paper and Code
Dec 01, 2022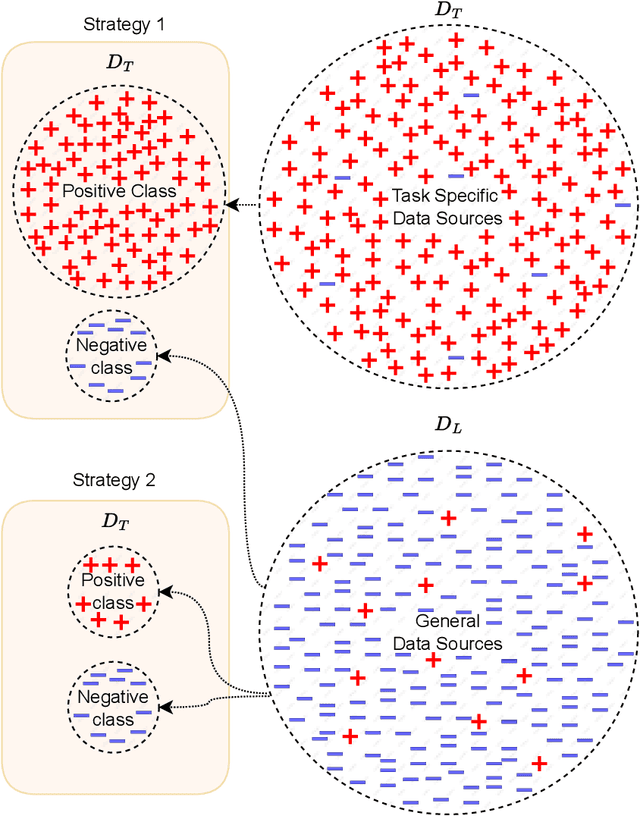



The sheer volume of online user-generated content has rendered content moderation technologies essential in order to protect digital platform audiences from content that may cause anxiety, worry, or concern. Despite the efforts towards developing automated solutions to tackle this problem, creating accurate models remains challenging due to the lack of adequate task-specific training data. The fact that manually annotating such data is a highly demanding procedure that could severely affect the annotators' emotional well-being is directly related to the latter limitation. In this paper, we propose the CM-Refinery framework that leverages large-scale multimedia datasets to automatically extend initial training datasets with hard examples that can refine content moderation models, while significantly reducing the involvement of human annotators. We apply our method on two model adaptation strategies designed with respect to the different challenges observed while collecting data, i.e. lack of (i) task-specific negative data or (ii) both positive and negative data. Additionally, we introduce a diversity criterion applied to the data collection process that further enhances the generalization performance of the refined models. The proposed method is evaluated on the Not Safe for Work (NSFW) and disturbing content detection tasks on benchmark datasets achieving 1.32% and 1.94% accuracy improvements compared to the state of the art, respectively. Finally, it significantly reduces human involvement, as 92.54% of data are automatically annotated in case of disturbing content while no human intervention is required for the NSFW task.