 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaching Historical Embeddings in Conversational Search
Paper and Code
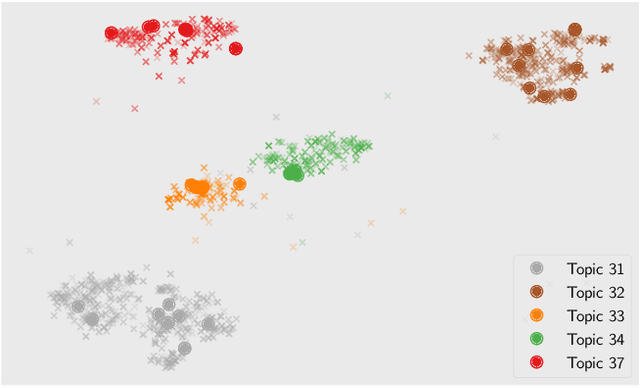
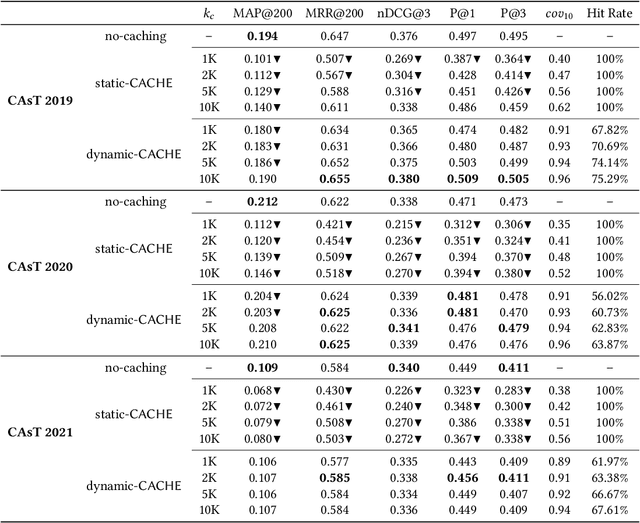
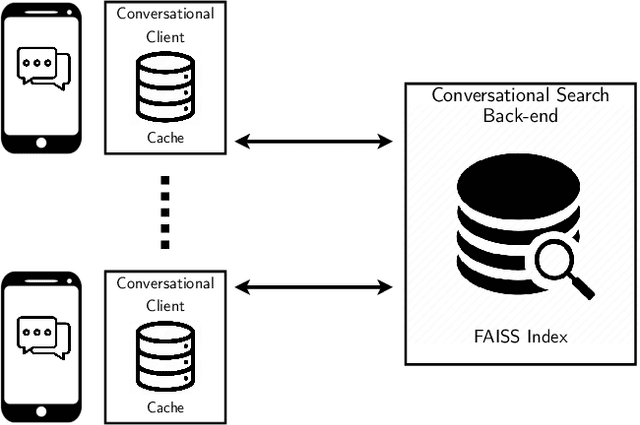
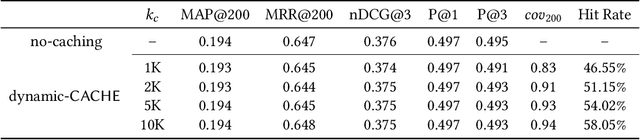
Rapid response, namely low latency, is fundamental in search applications; it is particularly so in interactive search sessions, such as those encountered in conversational settings. An observation with a potential to reduce latency asserts that conversational queries exhibit a temporal locality in the lists of documents retrieved. Motivated by this observation, we propose and evaluate a client-side document embedding cache, improving the responsiveness of conversational search systems. By leveraging state-of-the-art dense retrieval models to abstract document and query semantics, we cache the embeddings of documents retrieved for a topic introduced in the conversation, as they are likely relevant to successive queries. Our document embedding cache implements an efficient metric index, answering nearest-neighbor similarity queries by estimating the approximate result sets returned. We demonstrate the efficiency achieved using our cache via reproducible experiments based on TREC CAsT datasets, achieving a hit rate of up to 75% without degrading answer quality. Our achieved high cache hit rates significantly improve the responsiveness of conversational systems while likewise reducing the number of queries managed on the search back-end.