 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmalREC: A Dataset for Relation Extraction and Classification Leveraging Amalgamation of Large Language Models
Dec 29, 2024



Existing datasets for relation classification and extraction often exhibit limitations such as restricted relation types and domain-specific biases. This work presents a generic framework to generate well-structured sentences from given tuples with the help of Large Language Models (LLMs). This study has focused on the following major questions: (i) how to generate sentences from relation tuples, (ii) how to compare and rank them, (iii) can we combine strengths of individual methods and amalgamate them to generate an even bette quality of sentences, and (iv) how to evaluate the final dataset? For the first question, we employ a multifaceted 5-stage pipeline approach, leveraging LLMs in conjunction with template-guided generation. We introduce Sentence Evaluation Index(SEI) that prioritizes factors like grammatical correctness, fluency, human-aligned sentiment, accuracy, and complexity to answer the first part of the second question. To answer the second part of the second question, this work introduces a SEI-Ranker module that leverages SEI to select top candidate generations. The top sentences are then strategically amalgamated to produce the final, high-quality sentence. Finally, we evaluate our dataset on LLM-based and SOTA baselines for relation classification. The proposed dataset features 255 relation types, with 15K sentences in the test set and around 150k in the train set organized in, significantly enhancing relational diversity and complexity. This work not only presents a new comprehensive benchmark dataset for RE/RC task, but also compare different LLMs for generation of quality sentences from relational tuples.
TempTabQA: Temporal Question Answering for Semi-Structured Tables
Nov 14, 2023
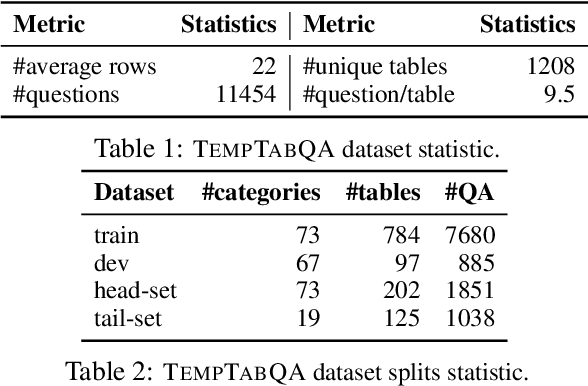


Semi-structured data, such as Infobox tables, often include temporal information about entities, either implicitly or explicitly. Can current NLP systems reason about such information in semi-structured tables? To tackle this question, we introduce the task of temporal question answering on semi-structured tables. We present a dataset, TempTabQA, which comprises 11,454 question-answer pairs extracted from 1,208 Wikipedia Infobox tables spanning more than 90 distinct domains. Using this dataset, we evaluate several state-of-the-art models for temporal reasoning. We observe that even the top-performing LLMs lag behind human performance by more than 13.5 F1 points. Given these results, our dataset has the potential to serve as a challenging benchmark to improve the temporal reasoning capabilities of NLP models.