 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty over Uncertainty: Investigating the Assumptions, Annotations, and Text Measurements of Economic Policy Uncertainty
Oct 09, 2020
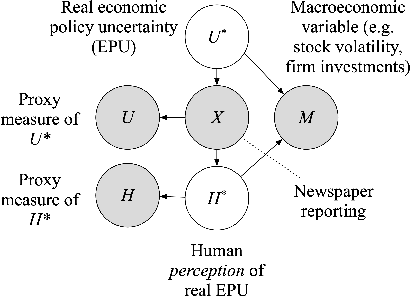

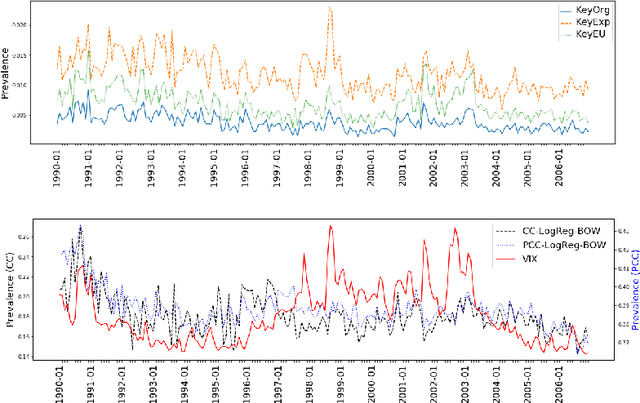
Methods and applications are inextricably linked in science, and in particular in the domain of text-as-data. In this paper, we examine one such text-as-data application, an established economic index that measures economic policy uncertainty from keyword occurrences in news. This index, which is shown to correlate with firm investment, employment, and excess market returns, has had substantive impact in both the private sector and academia. Yet, as we revisit and extend the original authors' annotations and text measurements we find interesting text-as-data methodological research questions: (1) Are annotator disagreements a reflection of ambiguity in language? (2) Do alternative text measurements correlate with one another and with measures of external predictive validity? We find for this application (1) some annotator disagreements of economic policy uncertainty can be attributed to ambiguity in language, and (2) switching measurements from keyword-matching to supervised machine learning classifiers results in low correlation, a concerning implication for the validity of the index.
* Accepted to the 2020 Natural Language Processing + Computational Social Science Workshop (NLP+CSS) at EMNLP
Grammatical Sequence Prediction for Real-Time Neural Semantic Parsing
Jul 25, 2019
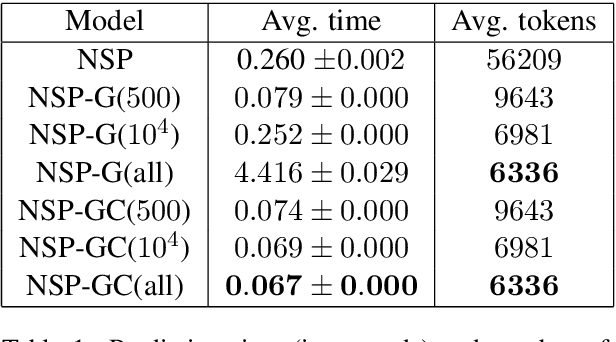
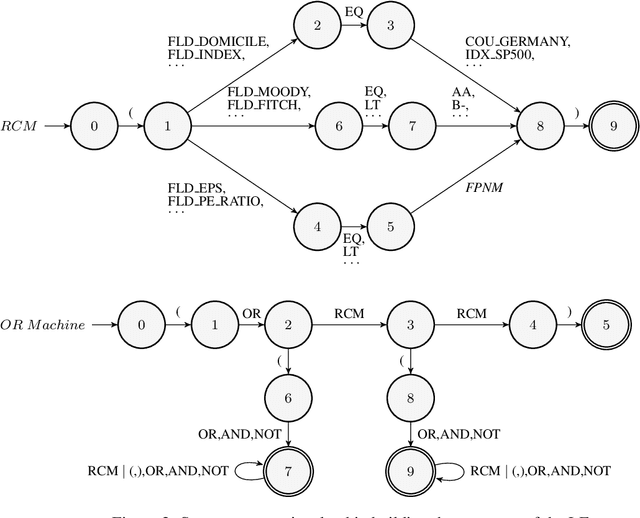
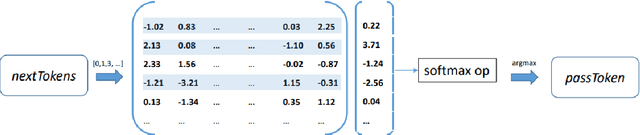
While sequence-to-sequence (seq2seq) models achieve state-of-the-art performance in many natural language processing tasks, they can be too slow for real-time applications. One performance bottleneck is predicting the most likely next token over a large vocabulary; methods to circumvent this bottleneck are a current research topic. We focus specifically on using seq2seq models for semantic parsing, where we observe that grammars often exist which specify valid formal representations of utterance semantics. By developing a generic approach for restricting the predictions of a seq2seq model to grammatically permissible continuations, we arrive at a widely applicable technique for speeding up semantic parsing. The technique leads to a 74% speed-up on an in-house dataset with a large vocabulary, compared to the same neural model without grammatical restrictions.
Discovering User Groups for Natural Language Generation
Jun 15, 2018
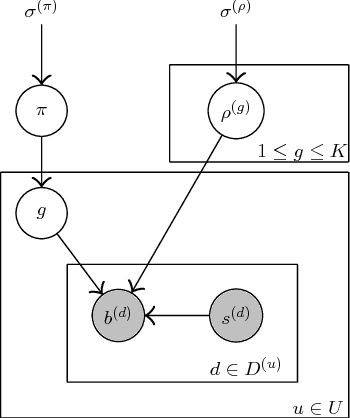
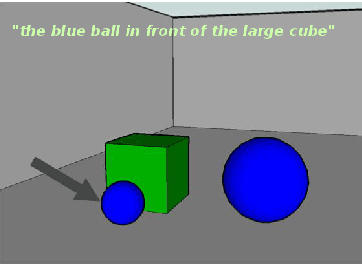
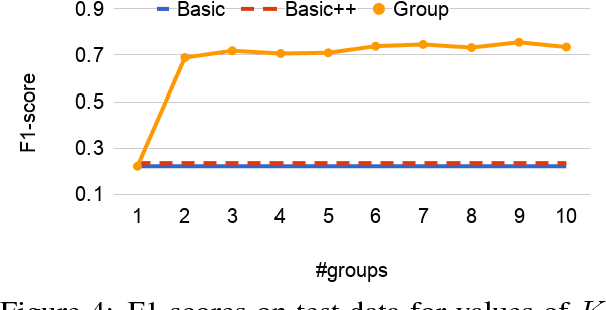
We present a model which predicts how individual users of a dialog system understand and produce utterances based on user groups. In contrast to previous work, these user groups are not specified beforehand, but learned in training. We evaluate on two referring expression (RE) generation tasks; our experiments show that our model can identify user groups and learn how to most effectively talk to them, and can dynamically assign unseen users to the correct groups as they interact with the system.