 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty over Uncertainty: Investigating the Assumptions, Annotations, and Text Measurements of Economic Policy Uncertainty
Paper and Code

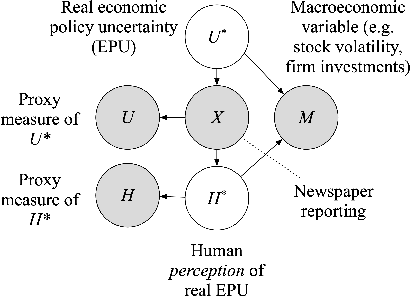

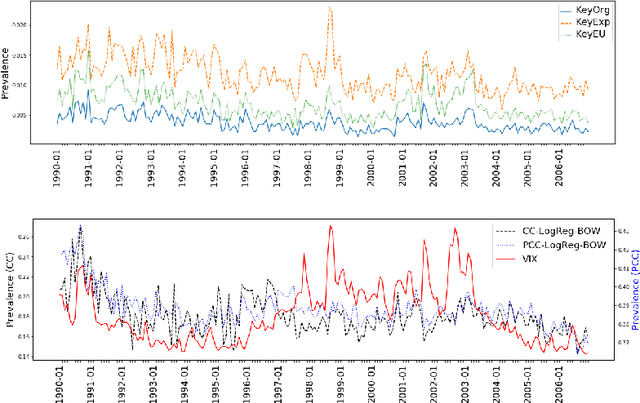
Methods and applications are inextricably linked in science, and in particular in the domain of text-as-data. In this paper, we examine one such text-as-data application, an established economic index that measures economic policy uncertainty from keyword occurrences in news. This index, which is shown to correlate with firm investment, employment, and excess market returns, has had substantive impact in both the private sector and academia. Yet, as we revisit and extend the original authors' annotations and text measurements we find interesting text-as-data methodological research questions: (1) Are annotator disagreements a reflection of ambiguity in language? (2) Do alternative text measurements correlate with one another and with measures of external predictive validity? We find for this application (1) some annotator disagreements of economic policy uncertainty can be attributed to ambiguity in language, and (2) switching measurements from keyword-matching to supervised machine learning classifiers results in low correlation, a concerning implication for the validity of the index.