 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Different Learning Styles for Improved Knowledge Distillation
Paper and Code
Dec 06, 2022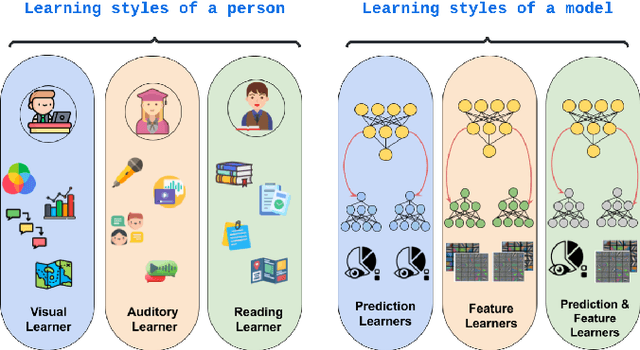
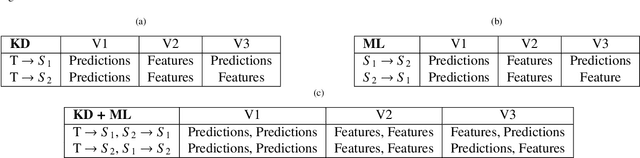
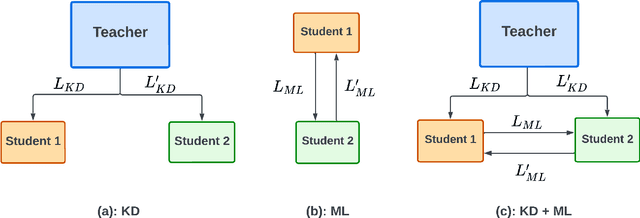
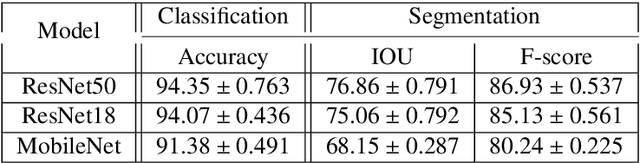
Learning style refers to a type of training mechanism adopted by an individual to gain new knowledge. As suggested by the VARK model, humans have different learning preferences like visual, auditory, etc., for acquiring and effectively processing information. Inspired by this concept, our work explores the idea of mixed information sharing with model compression in the context of Knowledge Distillation (KD) and Mutual Learning (ML). Unlike conventional techniques that share the same type of knowledge with all networks, we propose to train individual networks with different forms of information to enhance the learning process. We formulate a combined KD and ML framework with one teacher and two student networks that share or exchange information in the form of predictions and feature maps. Our comprehensive experiments with benchmark classification and segmentation datasets demonstrate that with 15% compression, the ensemble performance of networks trained with diverse forms of knowledge outperforms the conventional techniques both quantitatively and qualitatively.