 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-Intuitive Agent for Remote Embodied Visual Grounding
Paper and Code
Mar 24, 2021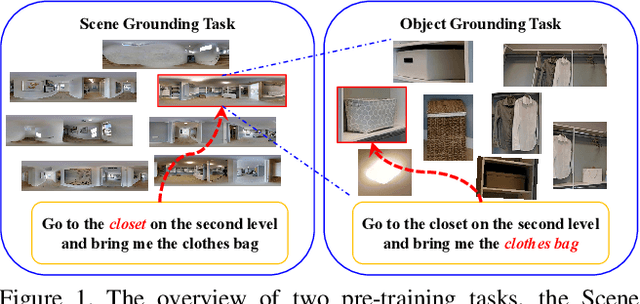

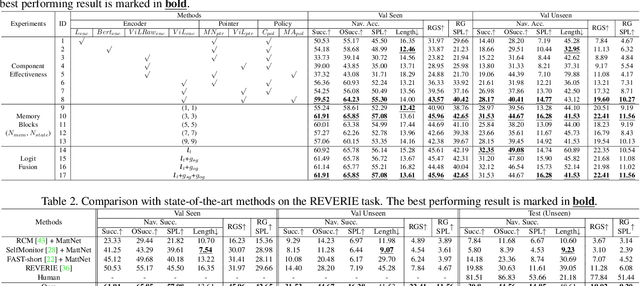
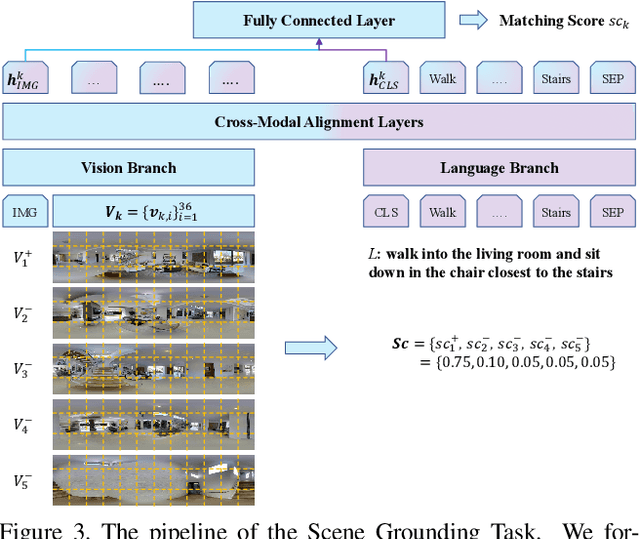
Humans learn from life events to form intuitions towards the understanding of visual environments and languages. Envision that you are instructed by a high-level instruction, "Go to the bathroom in the master bedroom and replace the blue towel on the left wall", what would you possibly do to carry out the task? Intuitively, we comprehend the semantics of the instruction to form an overview of where a bathroom is and what a blue towel is in mind; then, we navigate to the target location by consistently matching the bathroom appearance in mind with the current scene. In this paper, we present an agent that mimics such human behaviors. Specifically, we focus on the Remote Embodied Visual Referring Expression in Real Indoor Environments task, called REVERIE, where an agent is asked to correctly localize a remote target object specified by a concise high-level natural language instruction, and propose a two-stage training pipeline. In the first stage, we pretrain the agent with two cross-modal alignment sub-tasks, namely the Scene Grounding task and the Object Grounding task. The agent learns where to stop in the Scene Grounding task and what to attend to in the Object Grounding task respectively. Then, to generate action sequences, we propose a memory-augmented attentive action decoder to smoothly fuse the pre-trained vision and language representations with the agent's past memory experiences. Without bells and whistles, experimental results show that our method outperforms previous state-of-the-art(SOTA) significantly, demonstrating the effectiveness of our method.