 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Model and Any-Modality for Video Object Tracking
Paper and Code
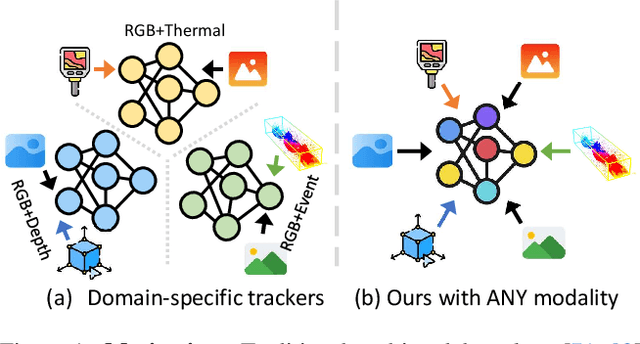

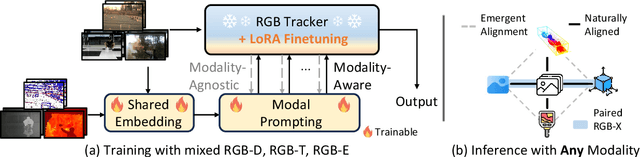

In the realm of video object tracking, auxiliary modalities such as depth, thermal, or event data have emerged as valuable assets to complement the RGB trackers. In practice, most existing RGB trackers learn a single set of parameters to use them across datasets and applications. However, a similar single-model unification for multi-modality tracking presents several challenges. These challenges stem from the inherent heterogeneity of inputs -- each with modality-specific representations, the scarcity of multi-modal datasets, and the absence of all the modalities at all times. In this work, we introduce Un-Track, a \underline{Un}ified Tracker of a single set of parameters for any modality. To handle any modality, our method learns their common latent space through low-rank factorization and reconstruction techniques. More importantly, we use only the RGB-X pairs to learn the common latent space. This unique shared representation seamlessly binds all modalities together, enabling effective unification and accommodating any missing modality, all within a single transformer-based architecture and without the need for modality-specific fine-tuning. Our Un-Track achieves +8.1 absolute F-score gain, on the DepthTrack dataset, by introducing only +2.14 (over 21.50) GFLOPs with +6.6M (over 93M) parameters, through a simple yet efficient prompting strategy. Extensive comparisons on five benchmark datasets with different modalities show that Un-Track surpasses both SOTA unified trackers and modality-specific finetuned counterparts, validating our effectiveness and practicality.