 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASMFS: Adaptive-Similarity-based Multi-modality Feature Selection for Classification of Alzheimer's Disease
Oct 16, 2020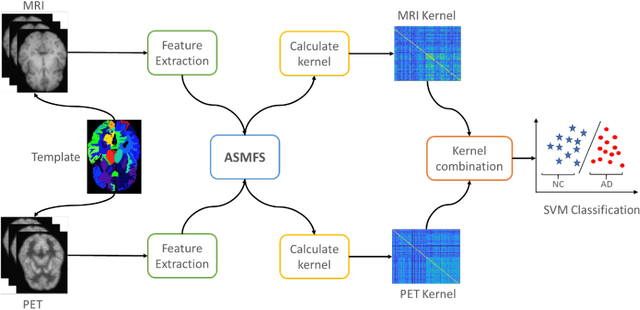
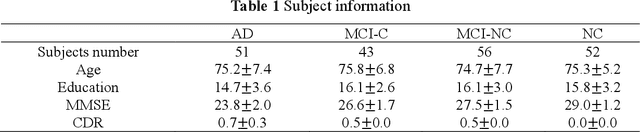
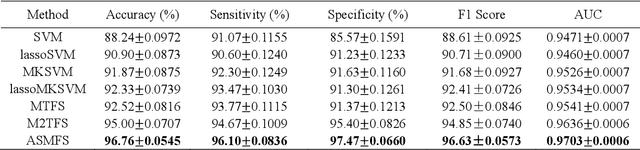
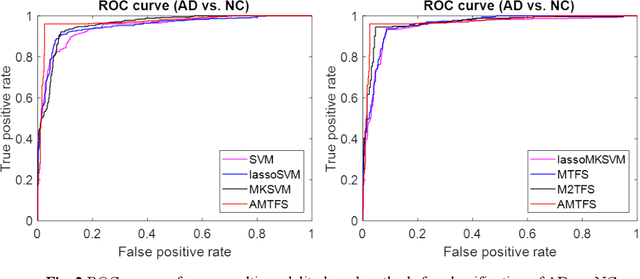
With the increasing amounts of high-dimensional heterogeneous data to be processed, multi-modality feature selection has become an important research direction in medical image analysis. Traditional methods usually depict the data structure using fixed and predefined similarity matrix for each modality separately, without considering the potential relationship structure across different modalities. In this paper, we propose a novel multi-modality feature selection method, which performs feature selection and local similarity learning simultaniously. Specially, a similarity matrix is learned by jointly considering different imaging modalities. And at the same time, feature selection is conducted by imposing sparse l_{2, 1} norm constraint. The effectiveness of our proposed joint learning method can be well demonstrated by the experimental results on Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, which outperforms existing the state-of-the-art multi-modality approaches.
DSU-net: Dense SegU-net for automatic head-and-neck tumor segmentation in MR images
Jun 12, 2020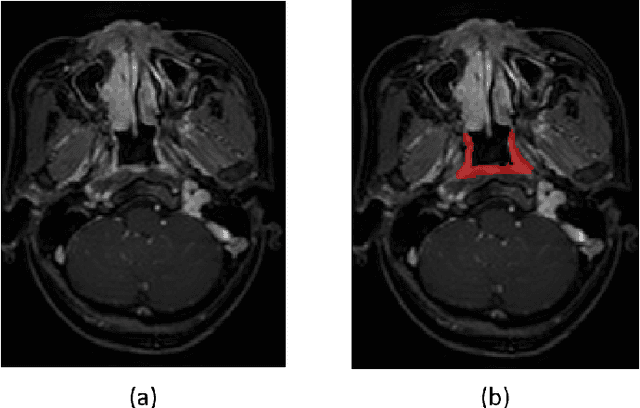

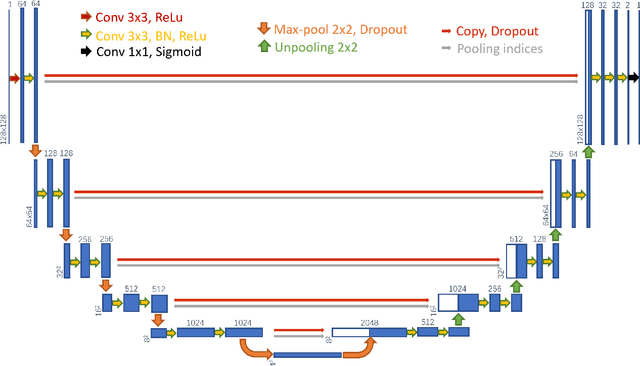

Precise and accurate segmentation of the most common head-and-neck tumor, nasopharyngeal carcinoma (NPC), in MRI sheds light on treatment and regulatory decisions making. However, the large variations in the lesion size and shape of NPC, boundary ambiguity, as well as the limited available annotated samples conspire NPC segmentation in MRI towards a challenging task. In this paper, we propose a Dense SegU-net (DSU-net) framework for automatic NPC segmentation in MRI. Our contribution is threefold. First, different from the traditional decoder in U-net using upconvolution for upsamling, we argue that the restoration from low resolution features to high resolution output should be capable of preserving information significant for precise boundary localization. Hence, we use unpooling to unsample and propose SegU-net. Second, to combat the potential vanishing-gradient problem, we introduce dense blocks which can facilitate feature propagation and reuse. Third, using only cross entropy (CE) as loss function may bring about troubles such as miss-prediction, therefore we propose to use a loss function comprised of both CE loss and Dice loss to train the network. Quantitative and qualitative comparisons are carried out extensively on in-house datasets, the experimental results show that our proposed architecture outperforms the existing state-of-the-art segmentation networks.