 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Segmentation at Arbitrary Granularity with Language Instruction
Dec 07, 2023This paper aims to achieve universal segmentation of arbitrary semantic level. Despite significant progress in recent years, specialist segmentation approaches are limited to specific tasks and data distribution. Retraining a new model for adaptation to new scenarios or settings takes expensive computation and time cost, which raises the demand for versatile and universal segmentation model that can cater to various granularity. Although some attempts have been made for unifying different segmentation tasks or generalization to various scenarios, limitations in the definition of paradigms and input-output spaces make it difficult for them to achieve accurate understanding of content at arbitrary granularity. To this end, we present UniLSeg, a universal segmentation model that can perform segmentation at any semantic level with the guidance of language instructions. For training UniLSeg, we reorganize a group of tasks from original diverse distributions into a unified data format, where images with texts describing segmentation targets as input and corresponding masks are output. Combined with a automatic annotation engine for utilizing numerous unlabeled data, UniLSeg achieves excellent performance on various tasks and settings, surpassing both specialist and unified segmentation models.
Bi-stream Pose Guided Region Ensemble Network for Fingertip Localization from Stereo Images
Feb 26, 2019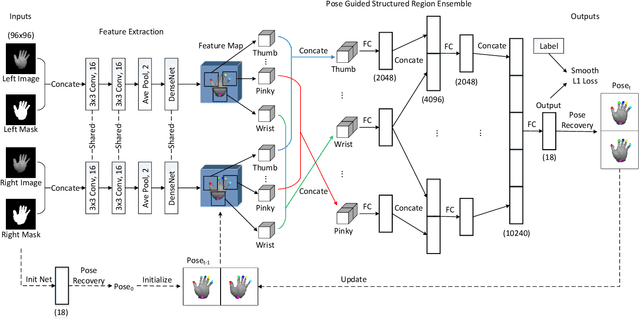
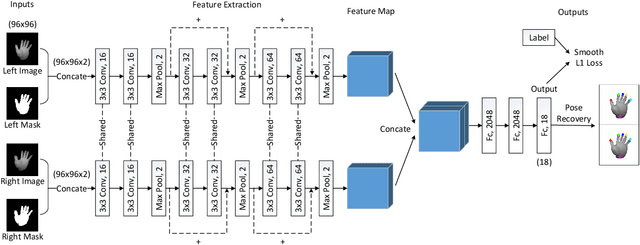
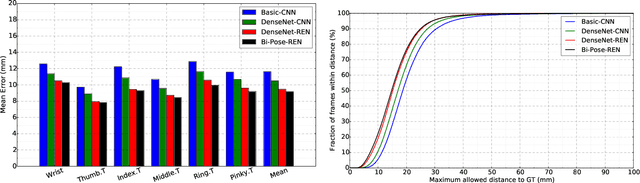
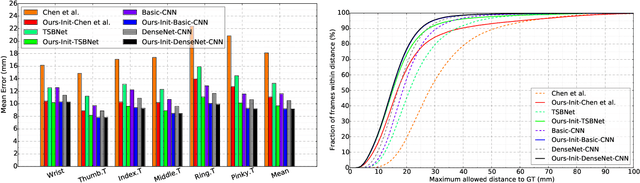
In human-computer interaction, it is important to accurately estimate the hand pose especially fingertips. However, traditional approaches for fingertip localization mainly rely on depth images and thus suffer considerably from the noise and missing values. Instead of depth images, stereo images can also provide 3D information of hands and promote 3D hand pose estimation. There are nevertheless limitations on the dataset size, global viewpoints, hand articulations and hand shapes in the publicly available stereo-based hand pose datasets. To mitigate these limitations and promote further research on hand pose estimation from stereo images, we propose a new large-scale binocular hand pose dataset called THU-Bi-Hand, offering a new perspective for fingertip localization. In the THU-Bi-Hand dataset, there are 447k pairs of stereo images of different hand shapes from 10 subjects with accurate 3D location annotations of the wrist and five fingertips. Captured with minimal restriction on the range of hand motion, the dataset covers large global viewpoint space and hand articulation space. To better present the performance of fingertip localization on THU-Bi-Hand, we propose a novel scheme termed Bi-stream Pose Guided Region Ensemble Network (Bi-Pose-REN). It extracts more representative feature regions around joint points in the feature maps under the guidance of the previously estimated pose. The feature regions are integrated hierarchically according to the topology of hand joints to regress the refined hand pose. Bi-Pose-REN and several existing methods are evaluated on THU-Bi-Hand so that benchmarks are provided for further research. Experimental results show that our new method has achieved the best performance on THU-Bi-Hand.
Interactive Hand Pose Estimation: Boosting accuracy in localizing extended finger joints
Jul 25, 2018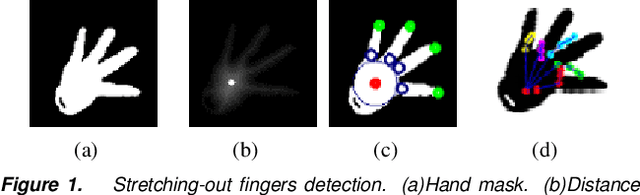
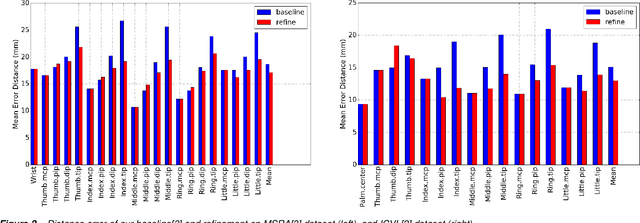
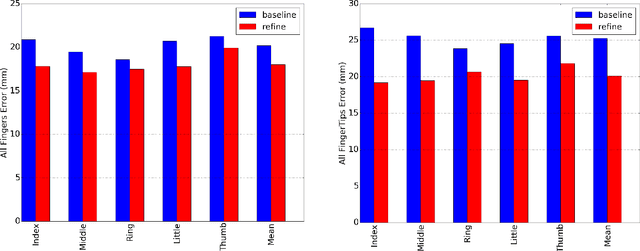
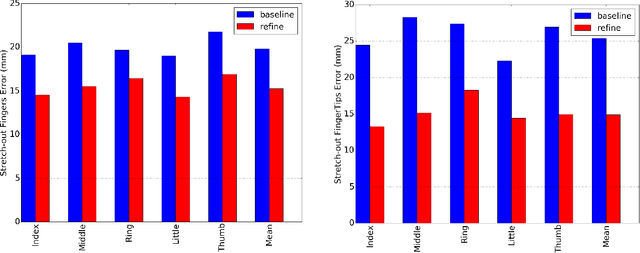
Accurate 3D hand pose estimation plays an important role in Human Machine Interaction (HMI). In the reality of HMI, joints in fingers stretching out, especially corresponding fingertips, are much more important than other joints. We propose a novel method to refine stretching-out finger joint locations after obtaining rough hand pose estimation. It first detects which fingers are stretching out, then neighbor pixels of certain joint vote for its new location based on random forests. The algorithm is tested on two public datasets: MSRA15 and ICVL. After the refinement stage of stretching-out fingers, errors of predicted HMI finger joint locations are significantly reduced. Mean error of all fingertips reduces around 5mm (relatively more than 20%). Stretching-out fingertip locations are even more precise, which in MSRA15 reduces 10.51mm (relatively 41.4%).
* Original publication available on https://doi.org/10.2352/ISSN.2470-1173.2018.2.VIPC-251
Pose Guided Structured Region Ensemble Network for Cascaded Hand Pose Estimation
Jun 24, 2018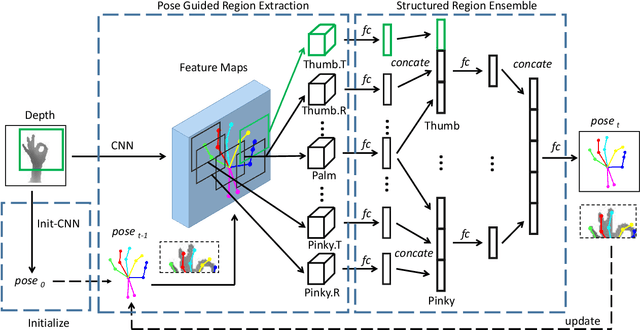
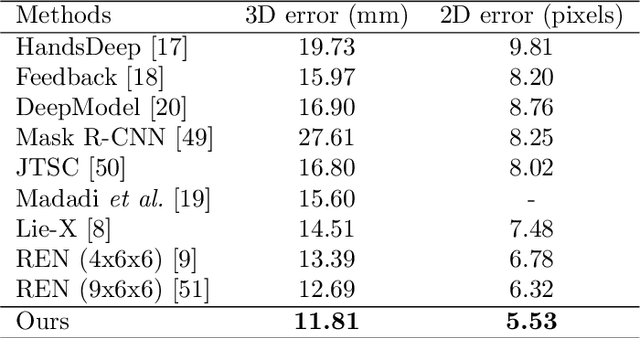
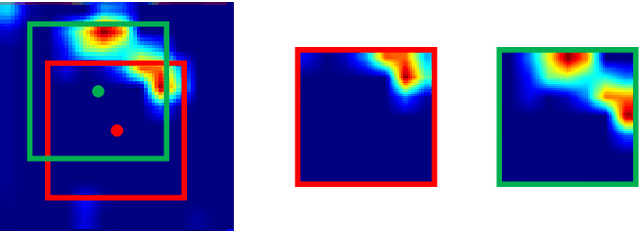
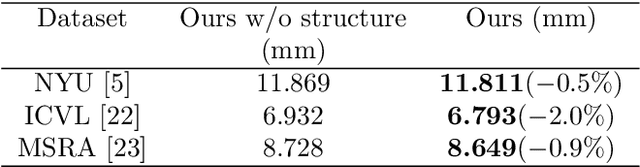
Hand pose estimation from a single depth image is an essential topic in computer vision and human computer interaction. Despite recent advancements in this area promoted by convolutional neural network, accurate hand pose estimation is still a challenging problem. In this paper we propose a Pose guided structured Region Ensemble Network (Pose-REN) to boost the performance of hand pose estimation. The proposed method extracts regions from the feature maps of convolutional neural network under the guide of an initially estimated pose, generating more optimal and representative features for hand pose estimation. The extracted feature regions are then integrated hierarchically according to the topology of hand joints by employing tree-structured fully connections. A refined estimation of hand pose is directly regressed by the proposed network and the final hand pose is obtained by utilizing an iterative cascaded method. Comprehensive experiments on public hand pose datasets demonstrate that our proposed method outperforms state-of-the-art algorithms.
Two-Stream Binocular Network: Accurate Near Field Finger Detection Based On Binocular Images
Apr 26, 2018
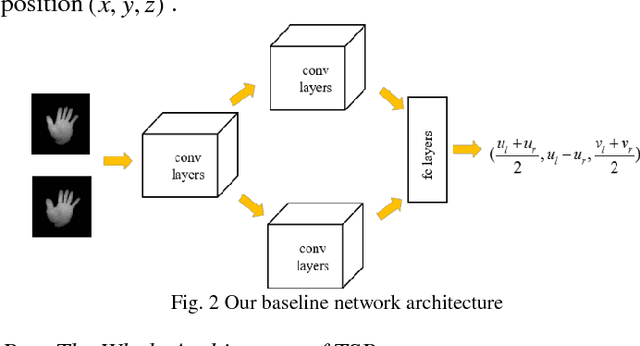
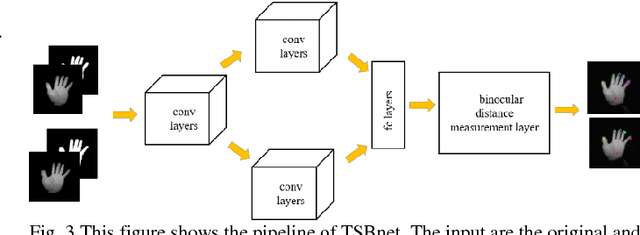
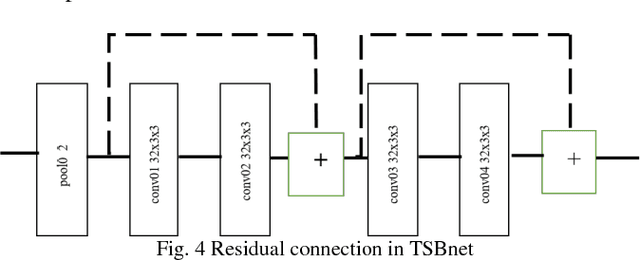
Fingertip detection plays an important role in human computer interaction. Previous works transform binocular images into depth images. Then depth-based hand pose estimation methods are used to predict 3D positions of fingertips. Different from previous works, we propose a new framework, named Two-Stream Binocular Network (TSBnet) to detect fingertips from binocular images directly. TSBnet first shares convolutional layers for low level features of right and left images. Then it extracts high level features in two-stream convolutional networks separately. Further, we add a new layer: binocular distance measurement layer to improve performance of our model. To verify our scheme, we build a binocular hand image dataset, containing about 117k pairs of images in training set and 10k pairs of images in test set. Our methods achieve an average error of 10.9mm on our test set, outperforming previous work by 5.9mm (relatively 35.1%).
* Published in: Visual Communications and Image Processing (VCIP), 2017 IEEE. Original IEEE publication available on https://ieeexplore.ieee.org/abstract/document/8305146/. Dataset available on https://sites.google.com/view/thuhand17
Towards Good Practices for Deep 3D Hand Pose Estimation
Jul 23, 2017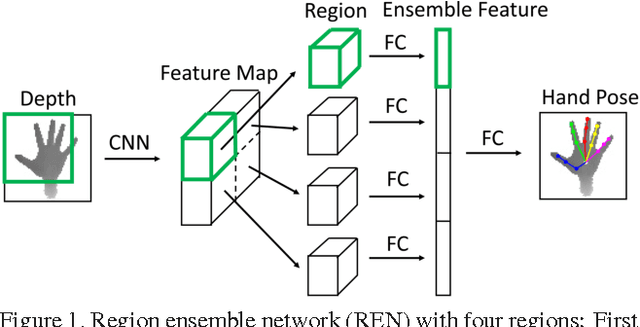

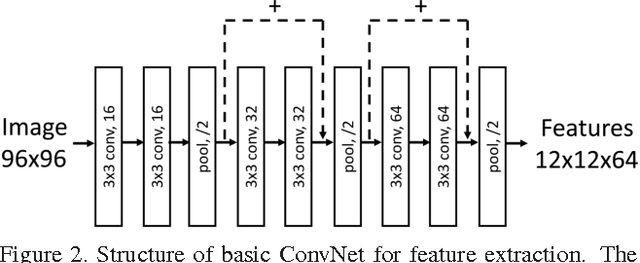
3D hand pose estimation from single depth image is an important and challenging problem for human-computer interaction. Recently deep convolutional networks (ConvNet) with sophisticated design have been employed to address it, but the improvement over traditional random forest based methods is not so apparent. To exploit the good practice and promote the performance for hand pose estimation, we propose a tree-structured Region Ensemble Network (REN) for directly 3D coordinate regression. It first partitions the last convolution outputs of ConvNet into several grid regions. The results from separate fully-connected (FC) regressors on each regions are then integrated by another FC layer to perform the estimation. By exploitation of several training strategies including data augmentation and smooth $L_1$ loss, proposed REN can significantly improve the performance of ConvNet to localize hand joints. The experimental results demonstrate that our approach achieves the best performance among state-of-the-art algorithms on three public hand pose datasets. We also experiment our methods on fingertip detection and human pose datasets and obtain state-of-the-art accuracy.
Region Ensemble Network: Improving Convolutional Network for Hand Pose Estimation
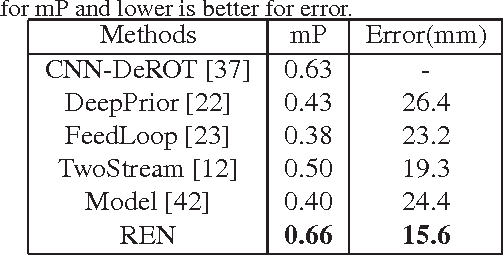
May 09, 2017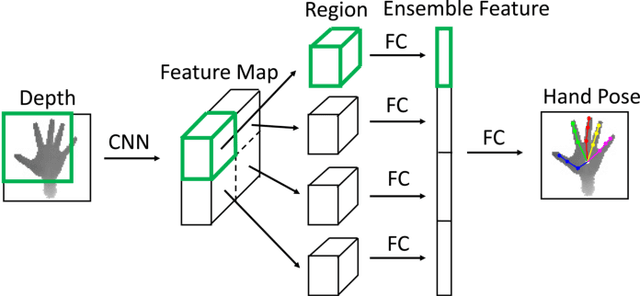
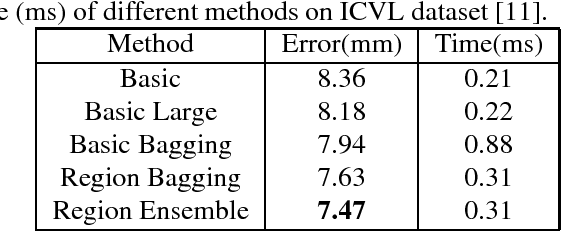
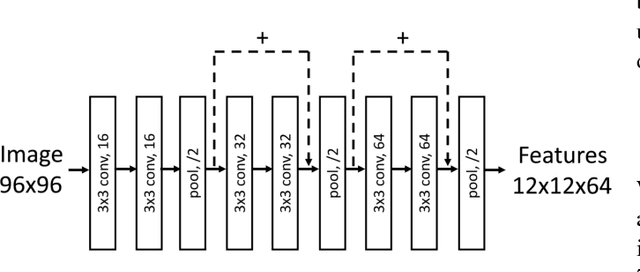

Hand pose estimation from monocular depth images is an important and challenging problem for human-computer interaction. Recently deep convolutional networks (ConvNet) with sophisticated design have been employed to address it, but the improvement over traditional methods is not so apparent. To promote the performance of directly 3D coordinate regression, we propose a tree-structured Region Ensemble Network (REN), which partitions the convolution outputs into regions and integrates the results from multiple regressors on each regions. Compared with multi-model ensemble, our model is completely end-to-end training. The experimental results demonstrate that our approach achieves the best performance among state-of-the-arts on two public datasets.